classSolution: deftwoSum(self, nums: List[int], target: int) -> List[int]: n = len(nums) for i inrange(n): for j inrange(i+1, n): if nums[i] + nums[j] == target: return [i, j] return []
哈希表
时间复杂度$O(N)$,空间复杂度$O(N)$,为哈希表的开销
1 2 3 4 5 6 7
classSolution: deftwoSum(self, nums: List[int], target: int) -> List[int]: idx = {} for i, x inenumerate(nums): if target - x in idx: return [idx[target - x], i] idx[x] = i
classSolution: deflongestConsecutive(self, nums: List[int]) -> int: nums_set = set(nums) ans = 0 for num in nums_set: # 遍历哈希表 # 没有更小的起始数时开始计算 if num - 1in nums_set: continue max_len = 1 while num + max_len in nums_set: max_len += 1 ans = max(ans, max_len)
return ans
一个小优化
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
classSolution: deflongestConsecutive(self, nums: List[int]) -> int: nums_set = set(nums) n = len(nums_set) ans = 0 for num in nums_set: # 遍历哈希表 # 没有更小的起始数时开始计算 if num - 1in nums_set: continue max_len = 1 while num + max_len in nums_set: max_len += 1 ans = max(ans, max_len) if ans * 2 >= n: # ans 不可能变得更大 break return ans
classSolution: defmaxArea(self, height: List[int]) -> int: area, ans = 0, 0 left, right = 0, len(height) - 1 while left < right: area = min(height[left], height[right]) * (right - left) ans = max(ans, area) if height[left] <= height[right]: left += 1 else: right -= 1
return ans
三数之和
给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i != j、i != k 且 j != k ,同时还满足 nums[i] + nums[j] + nums[k] == 0 。请你返回所有和为 0 且不重复的三元组。
classSolution: defthreeSum(self, nums: list[int]) -> list[list[int]]: nums.sort() n = len(nums) ans = [] for i inrange(n - 2): # 跳过重复数 if i > 0and nums[i] == nums[i - 1]: continue # 最小和>0,直接结束 if nums[i] + nums[i + 1] + nums[i + 2] > 0: break # 最大和<0,直接右移 if nums[i] + nums[-1] + nums[-2] < 0: continue j, k = i + 1, n - 1 while j < k: s = nums[i] + nums[j] + nums[k] if s == 0: ans.append([nums[i], nums[j], nums[k]]) j += 1 k -= 1 # 跳过重复数 while j < k and nums[k] == nums[k + 1]: k -= 1 while j < k and nums[j] == nums[j - 1]: j += 1 elif s < 0: j += 1 else: k -= 1 return ans
water = 0 for i inrange(n): water += min(leftmax[i], rightmax[i]) - height[i] # 两者小值-高度
return water
时间复杂度和空间复杂度都是O(n)
能否降低空间复杂度呢?
相向双指针
因为虽然不知道右侧最大值,但是右侧的max至少大于等于现在右指针的高度
在「谁小移动谁」的规则下,相遇的位置一定是最高的柱子,这个柱子是无法接水的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
classSolution: deftrap(self, height: List[int]) -> int: left, right = 0, len(height)-1 water = 0 leftmax, rightmax = 0, 0 while left < right: leftmax = max(leftmax, height[left]) rightmax = max(rightmax, height[right]) if leftmax < rightmax: water += leftmax - height[left] left += 1 else: water += rightmax - height[right] right -= 1
return water
单调栈
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
classSolution: deftrap(self, height: List[int]) -> int: n = len(height) st = [] ans = 0 for i inrange(n): # 当前柱子 height[i] 作为“右边界” # 如果比栈顶柱子高,说明可以形成一个“凹槽” while st and height[i] >= height[st[-1]]: bottom_h = height[st.pop()] # 如果栈空,说明左边没有更高的柱子,无法形成容器 iflen(st) == 0: break left = st[-1] dh = min(height[left], height[i]) - bottom_h ans += dh * (i - left - 1) st.append(i) return ans
classSolution: deflengthOfLongestSubstring(self, s: str) -> int: window = set() left = ans = 0 for right inrange(len(s)): while s[right] in window: window.remove(s[left]) # 删到没有right为止 left+=1 window.add(s[right]) ans = max(ans, right-left+1) retuan ans
找到字符串中所有字母异位词
给定两个字符串 s 和 p,找到 s 中所有 p 的 异位词 的子串,返回这些子串的起始索引。不考虑答案输出的顺序。
for i inrange(s_len - p_len): s_count[ord(s[i]) - ord("a")] -= 1# 剔除窗口头部字母 s_count[ord(s[i + p_len]) - ord("a")] += 1# 加入窗口下一个字母
if s_count == p_count: ans.append(i + 1)
return ans
方法二:定长窗口
定长,不断右移,判断是否匹配,匹配则加入左端点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
classSolution: deffindAnagrams(self, s: str, p: str) -> List[int]: cnt_p = Counter(p) # 统计 p 的每种字母的出现次数 cnt_s = Counter() # 统计 s 的长为 len(p) 的子串 t 的每种字母的出现次数 ans = []
for right, c inenumerate(s): cnt_s[c] += 1# 右端点字母进入窗口 left = right - len(p) + 1 if left < 0: # 窗口长度不足 len(p) continue if cnt_s == cnt_p: # t 和 p 的每种字母的出现次数都相同 ans.append(left) cnt_s[s[left]] -= 1# 左端点字母离开窗口 return ans
最小覆盖子串
给定两个字符串 s 和 t,长度分别是 m 和 n,返回 s 中的 最短窗口子串,使得该子串包含 t 中的每一个字符(包括重复字符)。如果没有这样的子串,返回空字符串 ""
示例 1:
1 2 3
输入:s = "ADOBECODEBANC", t = "ABC" 输出:"BANC" 解释:最小覆盖子串 "BANC" 包含来自字符串 t 的 'A'、'B' 和 'C'。
示例 2:
1 2 3
输入:s = "a", t = "a" 输出:"a" 解释:整个字符串 s 是最小覆盖子串。
示例 3:
1 2 3 4
输入: s = "a", t = "aa" 输出: "" 解释: t 中两个字符 'a' 均应包含在 s 的子串中, 因此没有符合条件的子字符串,返回空字符串。
创建计数表,不断滑动,如果子串涵盖t,就不断右移左端点直到不涵盖
移动过程中更新最短子串的左右端点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
classSolution: defminWindow(self, s: str, t: str) -> str: cnt_t = Counter(t) # t 中字母的出现次数 cnt_s = Counter() # s 子串字母的出现次数 ans_left, ans_right = -1, len(s) left = 0
for right, c inenumerate(s): # 移动子串右端点 cnt_s[c] += 1# 右端点字母移入子串 while cnt_s >= cnt_t: # 涵盖 if right - left < ans_right - ans_left: # 找到更短的子串 ans_left, ans_right = left, right cnt_s[s[left]] -= 1# 左端点字母移出子串 left += 1
classSolution: defminSubArrayLen(self, target: int, nums: List[int]) -> int: s = l =0 min_len = inf for r inrange(len(nums)): s += nums[r] while s >= target: # 满足要求 min_len = min(min_len, r - l + 1) s -= nums[l] l += 1# 左端点右移 return min_len if min_len <=n else0
prefix2 - prefix1 = k 转变为查找已经存进哈希表的值里有没有等于 prefix2 - k 的
注意,要在哈希表里默认加一个0,这样才能准确认到自身单元素的情况
1 2 3 4 5 6 7 8 9 10
classSolution: defsubarraySum(self, nums: List[int], k: int) -> int: prefix = defaultdict(int) prefix[0] = 1 ans = s = 0 for x in nums: s += x ans += prefix[s - k] prefix[s] += 1 return ans
改成计算元素和等于 k 的最长子数组
同样做法,但是这个时候要把计数改为最早出现位置
1 2 3 4 5 6 7 8 9 10 11 12 13 14
classSolution: deflongestSubarraySumK(self, nums: List[int], k: int) -> int: first = {0: -1} # 前缀和 -> 最早出现位置 s = 0 ans = 0
for i, x inenumerate(nums): s += x if s - k in first: ans = max(ans, i - first[s - k]) if s notin first: # 只记录第一次出现 first[s] = i
return ans
改成计算元素和等于 k 的最短子数组
1 2 3 4 5 6 7 8 9 10 11 12 13
classSolution: defshortestSubarraySumK(self, nums: List[int], k: int) -> int: last = {0: -1} # 前缀和 -> 最近一次出现位置 s = 0 ans = float('inf')
for i, x inenumerate(nums): s += x if s - k in last: ans = min(ans, i - last[s - k]) last[s] = i # 覆盖,保留最近位置
return ans if ans != float('inf') else0
滑动窗口最大值
给你一个整数数组 nums,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k 个数字。滑动窗口每次只向右移动一位。
classSolution: defmaxSlidingWindow(self, nums: List[int], k: int) -> List[int]: n = len(nums) dq = deque() ans = [] for i, num inenumerate(nums): # 1. 进 while dq and num >= nums[dq[-1]]: dq.pop() dq.append(i) # 2. 出 left = i - k + 1 # 因为每次只移动一步,所以最多只会有一个不合规 if dq[0] < left: dq.popleft() # 3. 记录答案 if left >= 0: ans.append(nums[dq[0]])
classSolution: deflongestSubarray(self, nums: List[int], limit: int) -> int: min_q = deque() max_q = deque() ans = left = 0 for i, num inenumerate(nums): # 1. 右边入 while min_q and num < nums[min_q[-1]]: min_q.pop() min_q.append(i) while max_q and num > nums[max_q[-1]]: max_q.pop() max_q.append(i) # 2. 左边出(只有不满足的时候出) while nums[max_q[0]] - nums[min_q[0]] > limit: left += 1 # 因为每次只移动一步,所以最多只会有一个不合规 if min_q[0] < left: min_q.popleft() if max_q[0] < left: max_q.popleft() ans = max(ans, i - left + 1) return ans
classSolution: defmerge(self, intervals: List[List[int]]) -> List[List[int]]: intervals.sort(key=lambda x: x[0]) # 按起点排序 ans = [] for x in intervals: if ans and x[0] <= ans[-1][1]: # 如果新区间起点小于合并区间中和殿 ans[-1][1] = max(ans[-1][1], x[1]) # 合并区间 else: ans.append(x) # 新开区间 return ans
classSolution: defrotate(self, nums: List[int], k: int) -> None: """ Do not return anything, modify nums in-place instead. """ n = len(nums) k = k % n
defreverse(l, r): while l < r: nums[l], nums[r] = nums[r], nums[l] l += 1 r -= 1
reverse(0, n - 1) reverse(0, k - 1) reverse(k, n - 1)
这种方法每个元素都被翻转两次,时间复杂度为O(n),空间复杂度为O(1),最推荐
切片拼接
相当于使用额外的数组
将原数组下标为i的元素放至新数组下标为 (i+k) mod n 的位置,最后将新数组拷贝至原数组即可
1 2 3 4 5 6 7
classSolution: defrotate(self, nums: List[int], k: int) -> None: """ Do not return anything, modify nums in-place instead. """ k %= len(nums) nums[:] = nums[-k:] + nums[:-k]
1 2 3 4 5 6 7 8 9 10 11 12 13
classSolution: defrotate(self, nums: List[int], k: int) -> None: """ Do not return anything, modify nums in-place instead. """ n = len(nums) k = k % n res = [0] * n
classSolution: defrotate(self, nums: List[int], k: int) -> None: """ Do not return anything, modify nums in-place instead. """ n = len(nums) k = k % n move = 0 for start inrange(n): if move >= n: break cur = start prev = nums[start]
whileTrue: nxt = (cur + k) % n nums[nxt], prev = prev, nums[nxt] cur = nxt move += 1
classSolution: defproductExceptSelf(self, nums: List[int]) -> List[int]: n = len(nums) pre = [1] * n for i inrange(1, n): pre[i] = pre[i - 1] * nums[i - 1] suf = [1] * n for i inrange(n - 2, -1, -1): suf[i] = suf[i + 1] * nums[i + 1] ans = [0] * n for i inrange(n): ans[i] = pre[i] * suf[i] return ans
怎么才能让空间复杂度降为O(1)呢
就不构建两个数组,直接把乘操作放到一个数组的两步
1 2 3 4 5 6 7 8 9 10 11 12 13 14
classSolution: defproductExceptSelf(self, nums: List[int]) -> List[int]: n = len(nums) ans = [1] * n # 前缀乘积 for i inrange(1, n): ans[i] = ans[i - 1] * nums[i - 1] # 后缀乘积(用一个变量来记录) suf = 1 for i inrange(n - 1, -1, -1): # 注意这里要从n-1开始了 ans[i] *= suf suf *= nums[i]
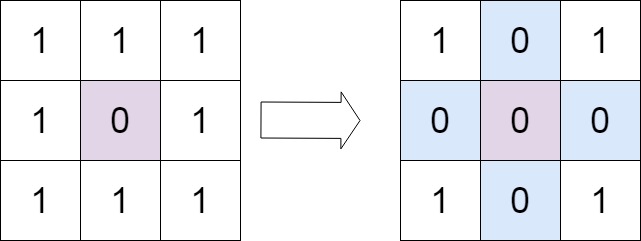
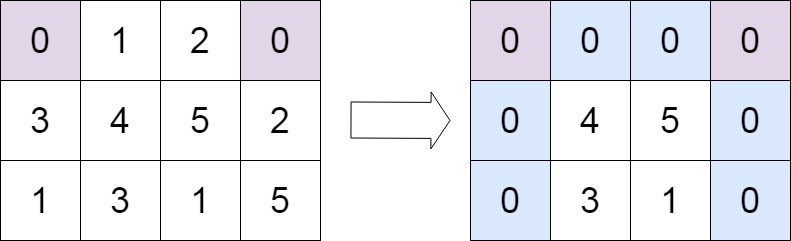
classSolution: defsetZeroes(self, matrix: List[List[int]]) -> None: """ Do not return anything, modify matrix in-place instead. """ m, n = len(matrix), len(matrix[0]) row, col = [False] * m, [False] * n
for i inrange(m): for j inrange(n): if matrix[i][j] == 0: row[i] = col[j] = True for i inrange(m): for j inrange(n): if row[i] or col[j]: matrix[i][j] = 0
classSolution: defsetZeroes(self, matrix: List[List[int]]) -> None: """ Do not return anything, modify matrix in-place instead. """ m, n = len(matrix), len(matrix[0]) flag_col0 = any(matrix[i][0] == 0for i inrange(m)) flag_row0 = any(matrix[0][j] == 0for j inrange(n))
for i inrange(1, m): # 无需遍历第一行 for j inrange(1, n): # 无需遍历第一列 if matrix[i][j] == 0: matrix[i][0] = 0 matrix[0][j] = 0
for i inrange(1, m): # 跳过第一行,留到最后修改 for j inrange(1, n): # 跳过第一列,留到最后修改 if matrix[i][0] == 0or matrix[0][j] == 0: matrix[i][j] = 0
# 如果第一列一开始就包含 0,那么把第一列全变成 0 if flag_col0: for i inrange(m): matrix[i][0] = 0 # 如果第一行一开始就包含 0,那么把第一行全变成 0 if flag_row0: for j inrange(n): matrix[0][j] = 0
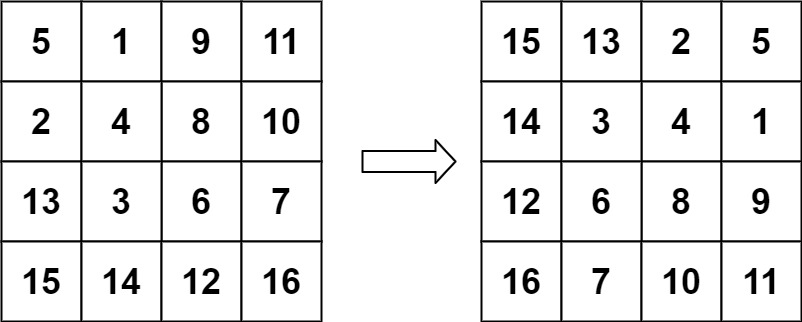
classSolution: defspiralOrder(self, matrix: List[List[int]]) -> List[int]: m, n = len(matrix), len(matrix[0]) ans = []
top, bottom = 0, m - 1 left, right = 0, n - 1
while top <= bottom and left <= right: for j inrange(left, right + 1): ans.append(matrix[top][j]) top += 1
for i inrange(top, bottom + 1): ans.append(matrix[i][right]) right -= 1
if top <= bottom: for j inrange(right, left - 1, -1): ans.append(matrix[bottom][j]) bottom -= 1
if left <= right: for i inrange(bottom, top - 1, -1): ans.append(matrix[i][left]) left += 1
return ans
时间复杂度为O(mn),空间复杂度为O(1)
标记法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
DIRS = (0, 1), (1, 0), (0, -1), (-1, 0)
classSolution: defspiralOrder(self, matrix: List[List[int]]) -> List[int]: m, n = len(matrix), len(matrix[0]) ans = [] i = j = di = 0 for _ inrange(m * n): ans.append(matrix[i][j]) matrix[i][j] = None x, y = i + DIRS[di][0], j + DIRS[di][1] if x < 0or x >= m or y < 0or y >= n or matrix[x][y] isNone: di = (di + 1) % 4
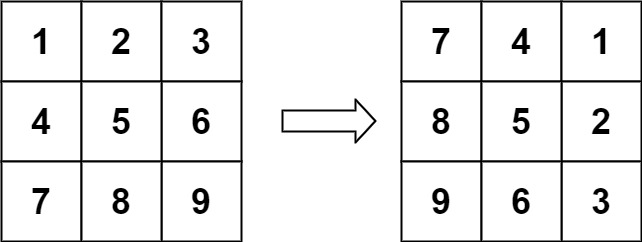
classSolution: defrotate(self, matrix: List[List[int]]) -> None: """ Do not return anything, modify matrix in-place instead. """ n = len(matrix) for i inrange(0, n // 2): for j inrange(i, n - i - 1): ( matrix[i][j], matrix[j][n - i - 1], matrix[n - i - 1][n - j - 1], matrix[n - j - 1][i], ) = ( matrix[n - j - 1][i], matrix[i][j], matrix[j][n - i - 1], matrix[n - i - 1][n - j - 1], )
用翻转代替旋转
因为直接用旋转需要思考,还不够直观,如果直接用多次翻转来等效旋转会更简单
顺时针旋转90°相当于(i, j) → (j, n - 1 - i)
这相当于先转置(i, j) → (j, i),而后对每行做一个翻转实现
1 2 3 4 5 6 7 8 9 10 11 12 13
classSolution: defrotate(self, matrix: List[List[int]]) -> None: """ Do not return anything, modify matrix in-place instead. """ m, n = len(matrix), len(matrix[0]) # 对角线翻转 for i inrange(m): for j inrange(i): matrix[i][j], matrix[j][i] = matrix[j][i], matrix[i][j] # 水平翻转 for row in matrix: row.reverse()
拓展:
如果要逆时针旋转90°呢?
旋转 90° 的标准坐标变换是(i, j) → (n - 1 - j, i)
那么相当于先转置后上下翻转
1 2 3 4 5 6 7 8 9 10 11
classSolution: defrotate(self, matrix: List[List[int]]) -> None: n = len(matrix)
# 对角线翻转 for i inrange(n): for j inrange(i): matrix[i][j], matrix[j][i] = matrix[j][i], matrix[i][j]
# 上下翻转(整体行顺序反转) matrix.reverse()
如果旋转180°相当于上下翻转再左右翻转
1 2 3 4 5 6 7 8
classSolution: defrotate(self, matrix: List[List[int]]) -> None: # 上下翻转 matrix.reverse() # 每一行左右翻转 for row in matrix: row.reverse()
classSolution: defsearchMatrix(self, matrix: List[List[int]], target: int) -> bool: m = len(matrix) n = len(matrix[0]) left, right = -1, m * n while left + 1 < right: mid = left + (right - left) // 2 r = mid // n c = mid % n x = matrix[r][c] if x == target: returnTrue elif x < target: left = mid else: right = mid returnFalse
搜索二维矩阵II
编写一个高效的算法来搜索 m x n 矩阵 matrix 中的一个目标值 target 。该矩阵具有以下特性:
classSolution: defsearchMatrix(self, matrix: List[List[int]], target: int) -> bool: m, n = len(matrix), len(matrix[0]) i, j = 0, n - 1 while i < m and j >= 0: cur = matrix[i][j]
if cur < target: i += 1 elif cur > target: j -= 1 else: returnTrue
classSolution: defsearchMatrix(self, matrix: List[List[int]], target: int) -> bool: m, n = len(matrix), len(matrix[0]) for row in matrix: if row[0] > target: returnFalse if row[-1] < target: continue if row[self.lower_bound(row, target)] == target: returnTrue
deflower_bound(self, nums: List[int], target: int): left, right = -1, len(nums) while left + 1 < right: mid = left + (right - left) // 2 if nums[mid] >= target: right = mid else: left = mid return right
# Definition for singly-linked list. # class ListNode: # def __init__(self, x): # self.val = x # self.next = None
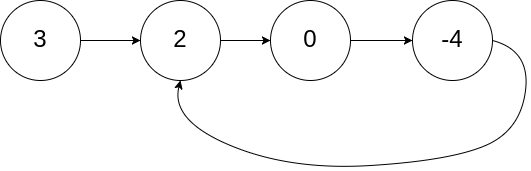
classSolution: defdetectCycle(self, head: Optional[ListNode]) -> Optional[ListNode]: seen = set() while head: if head in seen: return head seen.add(head) head = head.next returnNone
这种方法时间复杂度为O(n),空间复杂度也为O(n)
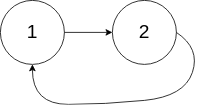
方法二:快慢指针
a = 头到入口距离
b = 入口到相遇点距离
c = 环长
相遇时:慢指针走了 a + b,快指针走了 a + b + k·c
因为 fast 速度是 slow 的 2 倍:2(a + b) = a + b + k·c
整理得到: $$ a + b = k·c\qquad a = k·c − b \qquad a = (c − b) + (k−1)c $$ 这意味着:从头走 a 步等价于从相遇点在环上走 c − b 步(再加若干整圈)
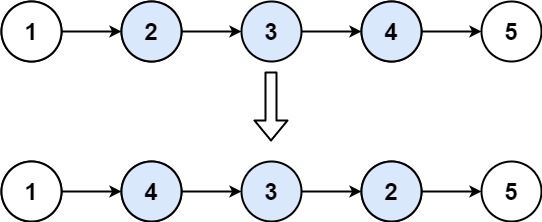
# Definition for singly-linked list. # class ListNode: # def __init__(self, val=0, next=None): # self.val = val # self.next = next classSolution: defreverseKGroup(self, head: Optional[ListNode], k: int) -> Optional[ListNode]: n = 0 cur = head while cur: n += 1# 获取链表长度 cur = cur.next
# Definition for singly-linked list. # class ListNode: # def __init__(self, val=0, next=None): # self.val = val # self.next = next classSolution: defaddTwoNumbers( self, l1: Optional[ListNode], l2: Optional[ListNode] ) -> Optional[ListNode]: st1, st2 = [], []
while l1: st1.append(l1.val) l1 = l1.next while l2: st2.append(l2.val) l2 = l2.next
carry = 0 head = None while st1 or st2 or carry: if st1: carry += st1.pop() if st2: carry += st2.pop() # 尾插法 node = ListNode(carry%10) node.next = head head = node
carry //= 10
return head
但是额外用栈,空间复杂度变为O(n)
删除链表中的节点
有一个单链表的 head,我们想删除它其中的一个节点 node
链表的所有值都是 唯一的,并且保证给定的节点 node 不是链表中的最后一个节点
删除节点并不是指从内存中删除它。这里的意思是:
给定节点的值不应该存在于链表中
链表中的节点数应该减少 1
node 前面的所有值顺序相同
node 后面的所有值顺序相同
1 2 3 4 5 6 7 8 9 10 11 12 13 14
# Definition for singly-linked list. # class ListNode: # def __init__(self, x): # self.val = x # self.next = None
# Definition for singly-linked list. # class ListNode: # def __init__(self, val=0, next=None): # self.val = val # self.next = next classSolution: defremoveNthFromEnd(self, head: Optional[ListNode], n: int) -> Optional[ListNode]: stack = list() dummy = ListNode(0, head) cur = dummy while cur: stack.append(cur) cur = cur.next # 每弹一次,相当于从后往前移动一个位置 for _ inrange(n): stack.pop() # 获取删除节点的前驱 prev = stack[-1] prev.next = prev.next.next
return dummy.next
时间复杂度O(n),空间复杂度O(n),但是只扫描链表一次
方法二:双指针
让快指针先走n步,然后移动慢指针
那么当快指针走到链表尾部时,慢指针到达倒数第 n 个位置的前驱
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
# Definition for singly-linked list. # class ListNode: # def __init__(self, val=0, next=None): # self.val = val # self.next = next classSolution: defremoveNthFromEnd(self, head: Optional[ListNode], n: int) -> Optional[ListNode]: left = right = dummy = ListNode(next = head) # 用哨兵是避免删除后为空报错 for _ inrange(n): # 右指针先向右走 n 步 right = right.next while right.next: # 左右指针一起走 left = left.next right = right.next left.next = left.next.next# 左指针的下一个节点就是倒数第 n 个节点 return dummy.next
时间复杂度O(n),空间复杂度O(1),且只扫描链表一次,快慢指针是最优雅的做法
删除排序链表中的重复元素
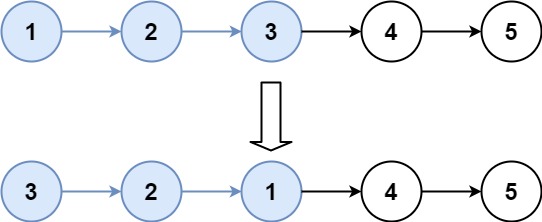
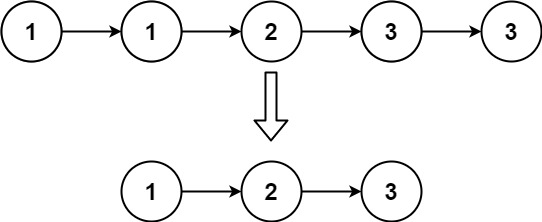
给定一个已排序的链表的头 head , 删除所有重复的元素,使每个元素只出现一次,返回已排序的链表
示例
1 2
输入:head = [1,1,2,3,3] 输出:[1,2,3]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
# Definition for singly-linked list. # class ListNode: # def __init__(self, val=0, next=None): # self.val = val # self.next = next classSolution: defdeleteDuplicates(self, head: Optional[ListNode]) -> Optional[ListNode]: if head isNone: return head cur = head while cur.next: # 注意这里是看cur.next if cur.next.val == cur.val: cur.next = cur.next.next else: cur = cur.next return head
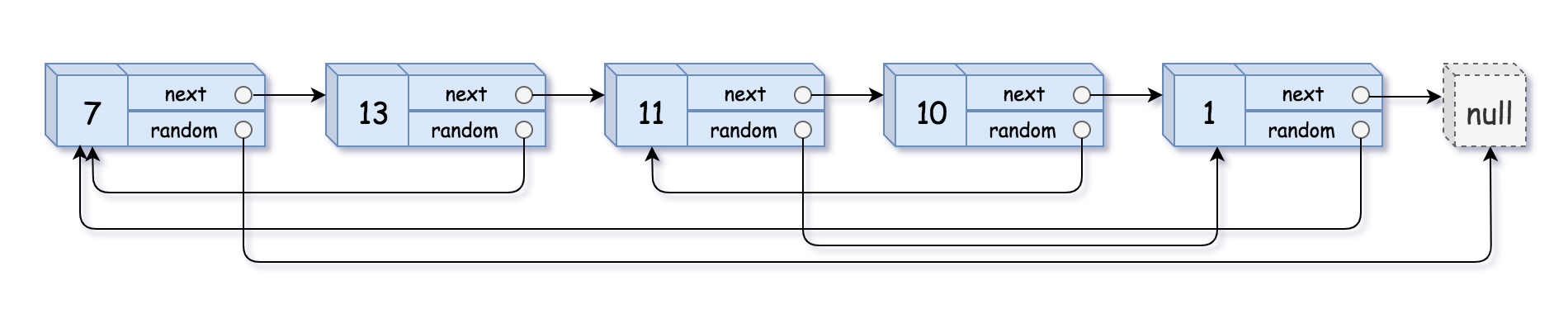
""" # Definition for a Node. class Node: def __init__(self, x: int, next: 'Node' = None, random: 'Node' = None): self.val = int(x) self.next = next self.random = random """
classSolution: defcopyRandomList(self, head: "Optional[Node]") -> "Optional[Node]": if head isNone: returnNone
node_map = {} cur = head # 第一遍:建立原节点 -> 新节点映射 while cur: node_map[cur] = Node(cur.val) cur = cur.next
# 第二遍:连接 next 和 random cur = head while cur: # 用get主要是处理None的情况,能正常返回None # node_map[cur.next]碰到None会报错 node_map[cur].next = node_map.get(cur.next) node_map[cur].random = node_map.get(cur.random) cur = cur.next
# Definition for singly-linked list. # class ListNode: # def __init__(self, val=0, next=None): # self.val = val # self.next = next classSolution: defmiddleNode(self, head: Optional[ListNode]) -> Optional[ListNode]: slow = head fast = head while fast and fast.next: slow = slow.next fast = fast.next.next return slow
# Definition for singly-linked list. # class ListNode: # def __init__(self, val=0, next=None): # self.val = val # self.next = next classSolution: defmiddleNode(self, head: Optional[ListNode]) -> Optional[ListNode]: # 快慢指针找中点 slow = head fast = head while fast and fast.next: pre = slow # 记录slow的前一个位置,方便断开 slow = slow.next fast = fast.next.next pre.next = None# 断开 slow 的前一个节点和 slow 的连接 return slow
defmergeTwoLists( self, list1: Optional[ListNode], list2: Optional[ListNode] ) -> Optional[ListNode]: # 合并两个有序链表 cur = dummy = ListNode(0) while list1 and list2: if list1.val < list2.val: cur.next = list1 list1 = list1.next else: cur.next = list2.next list2 = list2.next cur = cur.next
if list1: cur.next = list1 if list2: cur.next = list2
return dummy.next
defsortList(self, head: Optional[ListNode]) -> Optional[ListNode]: ifnot head ornot head.next: return head head2 = self.middleNode(head) # 递归排序 head = self.sortList(head) head2 = self.sortList(head2)
# Definition for singly-linked list. # class ListNode: # def __init__(self, val=0, next=None): # self.val = val # self.next = next classSolution: defgetListLength(self, head: Optional[ListNode]) -> int: # 获取链表长度 length = 0 while head: length += 1 head = head.next return length
defsplitList(self, head: Optional[ListNode], size: int) -> Optional[ListNode]: cur = head for _ inrange(size - 1): if cur isNone: break cur = cur.next # 如果链表长度 <= size if cur isNoneor cur.nextisNone: returnNone# 不做任何操作,返回空节点
# Definition for singly-linked list. # class ListNode: # def __init__(self, val=0, next=None): # self.val = val # self.next = next classSolution: defmergeKLists(self, lists: List[Optional[ListNode]]) -> Optional[ListNode]: m = len(lists) if m == 0: returnNone if m == 1: return lists[0] # 无需合并,直接返回
left = self.mergeKLists(lists[: m // 2]) # 合并左半部分 right = self.mergeKLists(lists[m // 2 :]) # 合并右半部分 returnself.mergeTwoLists(left, right) # 最后把左半和右半合并
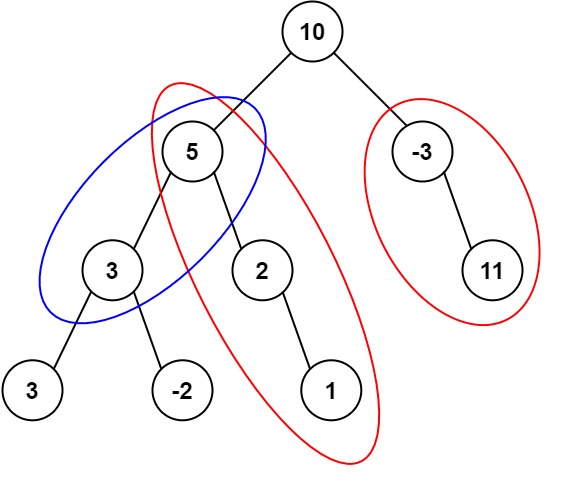
classSolution: defmaxPathSum(self, root: Optional[TreeNode]) -> int: if root isNone: return0
ans = float("-inf")
defdfs(node): nonlocal ans if node isNone: return0 left = dfs(node.left) right = dfs(node.right) ans = max(ans, left + right + node.val) returnmax(max(left, right) + node.val, 0) dfs(root) return ans
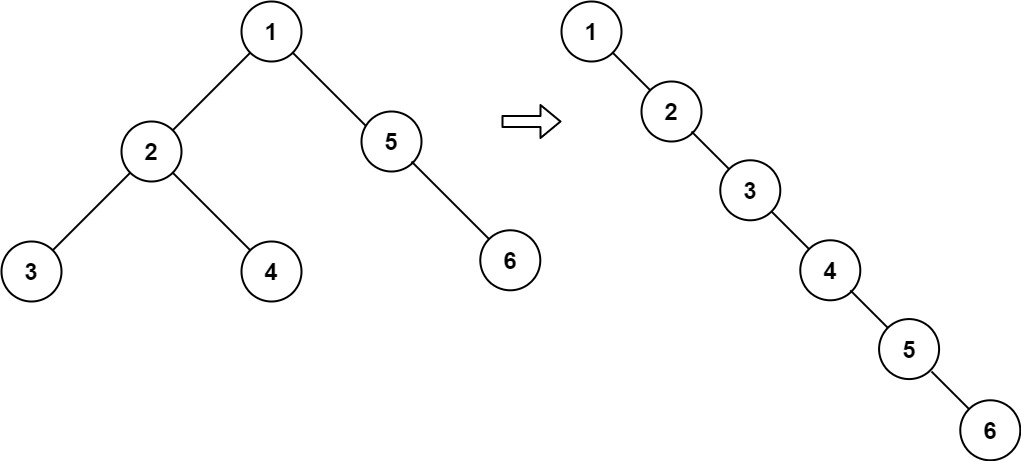
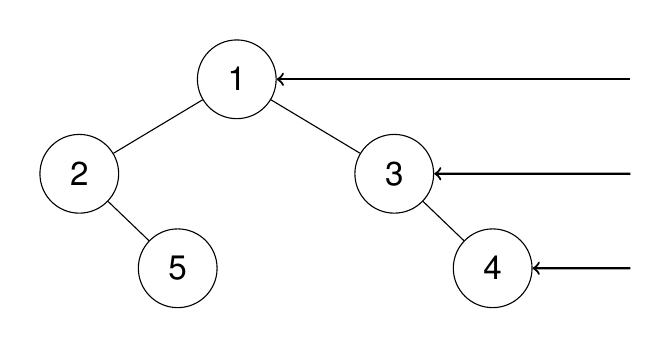
二叉树展开为链表
给你二叉树的根结点 root ,请你将它展开为一个单链表:
展开后的单链表应该同样使用 TreeNode ,其中 right 子指针指向链表中下一个结点,而左子指针始终为 null
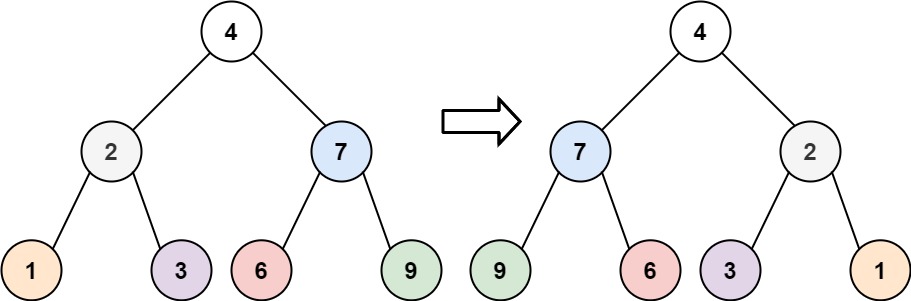
classSolution: definvertTree(self, root: Optional[TreeNode]) -> Optional[TreeNode]: if root isNone: returnNone left = self.invertTree(root.left) right = self.invertTree(root.right) root.left = right root.right = left return root
classSolution: defrightSideView(self, root: Optional[TreeNode]) -> List[int]: if root isNone: return [] ans = [] q = [root] while q: ans.append(q[-1].val) q_next_level = [] for node in q: if node.left: q_next_level.append(node.left) if node.right: q_next_level.append(node.right) q = q_next_level return ans
找树左下角的值
给定一个二叉树的 根节点root,请找出该二叉树的 最底层 最左边 节点的值。
假设二叉树中至少有一个节点
示例:
1 2
输入: [1,2,3,4,null,5,6,null,null,7] 输出: 7
可以采用层序遍历,然后输出最左的值
1 2 3 4 5 6 7 8 9 10 11 12 13
classSolution: deffindBottomLeftValue(self, root: Optional[TreeNode]) -> int: dq = deque([root]) ans = root.val while dq: ans = dq[0].val for _ inrange(len(dq)): node = dq.popleft() if node.left: dq.append(node.left) if node.right: dq.append(node.right) return ans
或者从右往左读,这样最后一个读的节点就是左下角的点
1 2 3 4 5 6 7 8 9 10
classSolution: deffindBottomLeftValue(self, root: Optional[TreeNode]) -> int: dq = deque([root]) while dq: node = dq.popleft() if node.right: dq.append(node.right) if node.left: dq.append(node.left) return node.val
classSolution: defcanFinish(self, numCourses: int, prerequisites: List[List[int]]) -> bool: graph = [[] for _ inrange(numCourses)] for a, b in prerequisites: graph[b].append(a)
color = [0] * numCourses # 返回 True 表示找到了环 defdfs(x: int) -> bool: color[x] = 1# x 正在访问中 for nxt in graph[x]: # 情况一:colors == 1,表示发生循环依赖,找到了环 # 情况二:colors == 0,没有访问过,继续递归获取信息 # 情况三:colors == 2,重复访问,和之前一样无法找到环,跳过 if color[nxt] == 1or (color[nxt] == 0and dfs(nxt)): returnTrue color[x] = 2 returnFalse
for i inrange(numCourses): if color[i] == 0and dfs(i): returnFalse returnTrue
# Your Trie object will be instantiated and called as such: # obj = Trie() # obj.insert(word) # param_2 = obj.search(word) # param_3 = obj.startsWith(prefix)
classSolution: defcombinationSum(self, candidates: List[int], target: int) -> List[List[int]]: ans = [] n = len(candidates)
defdfs(index, total, curr): if index == n: if total == target: # 如果当前总和等于目标值,添加当前组合到结果列表 ans.append(curr) return rest = target - total # 计算剩余的目标值 up = rest // candidates[index] # 计算当前候选数最多可以使用多少次 , 向下取整 for i inrange(up + 1): # 从 0 到 up 次使用当前候选数 dfs( index + 1, total + i * candidates[index], curr + i * [candidates[index]], )
dfs(0, 0, []) # 从索引 0 开始,初始总和为 0,当前组合为空 return ans
如果不显式写选几个,可以让递归栈自己判断
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
classSolution: defcombinationSum(self, candidates: List[int], target: int) -> List[List[int]]: ans = [] n = len(candidates)
defdfs(index, total, curr): if index == n: if total == target: # 如果当前总和等于目标值,添加当前组合到结果列表 ans.append(curr) return dfs(index + 1, total, curr) # 不选 if total + candidates[index] <= target: # 如果使用当前候选数不会超过目标值 # 使用当前候选数一次,继续递归 dfs(index, total + candidates[index], curr + [candidates[index]])
dfs(0, 0, []) return ans
分割回文串
给你一个字符串 s,请你将 s 分割成一些 子串,使每个子串都是 回文串 。返回 s 所有可能的分割方案。
classSolution: defpermute(self, nums: List[int]) -> List[List[int]]: n = len(nums) # ans 用来存储所有排列结果 ans = [] # curr 表示当前正在生成的排列 curr = [] # used 标记每个数字当前是否已经被放入 curr used = [False] * n
defdfs(index): # 当 index == n,说明 n 个位置都已经填满,得到一个完整排列 if index == n: ans.append(curr[:]) return
# 当前这个位置可以尝试填写任意一个还没有使用过的数字 for i inrange(n): ifnot used[i]: # 选择 nums[i] used[i] = True curr.append(nums[i])
# 继续填写下一个位置 dfs(index + 1)
# 回溯,撤销选择 curr.pop() used[i] = False
dfs(0) return ans
单词搜索
给定一个 m x n 二维字符网格 board 和一个字符串单词 word 。如果 word 存在于网格中,返回 true ;否则,返回 false
classSolution: defsolveNQueens(self, n: int) -> List[List[str]]: ans = [] col = [0] * n # 假设先全放0列
defvalid(r, c): # 判断当前位置是否有效 for R inrange(r): # 根据之前的Q位置 C = col[R] if r + c == R + C or r - c == R - C: returnFalse # 如果都判断通过返回True returnTrue
defdfs(r, s): if r == n: ans.append(["." * c + "Q" + "." * (n - 1 - c) for c in col]) return for c in s: if valid(r, c): col[r] = c dfs(r + 1, s - {c})
dfs(0, set(range(n))) return ans
因为每次valid判断都要遍历,所以时间复杂度为O(n*n!),空间复杂度为O(n)
二分查找
开区间写法
1 2 3 4 5 6 7 8 9 10 11 12
deflower_bound(nums: List[int], target: int): left, right = -1, len(nums) # 开区间 (left, right) while left+1 < right: # 区间不为空 mid = left + (right-left)//2 # 循环不变量: # nums[left] < target # nums[right] >= target if nums[mid] >= target: right = mid # 范围缩小到 (left, mid) else: left = mid # 范围缩小到 (mid, right) return right
classSolution: defsearchMatrix(self, matrix: List[List[int]], target: int) -> bool: m = len(matrix) n = len(matrix[0]) left, right = -1, m * n while left + 1 < right: mid = left + (right - left) // 2 r = mid // n c = mid % n x = matrix[r][c] if x == target: returnTrue elif x < target: left = mid else: right = mid returnFalse
classSolution: deffindMedianSortedArrays(self, a: List[int], b: List[int]) -> float: merged = a + b merged.sort()
s = len(merged) k = (s - 1) // 2 return merged[k] if s % 2else (merged[k] + merged[k + 1]) / 2
直接合并两个数组再sort,找到中位数
简单,但是时间复杂度O((m+n)log(m+n)),空间复杂度O(m+n)
双指针做法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
classSolution: deffindMedianSortedArrays(self, nums1: List[int], nums2: List[int]) -> float: m, n = len(nums1), len(nums2) total = m + n mid = total // 2 i = j = 0 prev = curr = 0 for _ inrange(mid+1): prev = curr
if i < m and (j >= n or nums1[i] <= nums2[j]): curr = nums1[i] i +=1 else: curr = nums2[j] j+=1 return curr if total%2else (prev+curr)/2
classSolution: defminTaps(self, n: int, ranges: List[int]) -> int: right_most = [0] * (n + 1) for i, r inenumerate(ranges): left = max(i - r, 0) right_most[left] = max(right_most[left], i + r) # 计算left位置能到达的最远端
ans = 0 cur_right = 0 next_right = 0 for i inrange(n): # 如果走到 n-1 时没有返回 -1,那么必然可以到达 n next_right = max(next_right, right_most[i]) if i == cur_right: if i == next_right: # 如果覆盖面积扩不大了,说明无法覆盖 return -1 cur_right = next_right ans += 1 return ans
# 从小到大枚举每个金额 for i inrange(1, amount + 1): # 枚举最后一个使用的硬币面额 for coin in coins: # 只有当前金额 i 能放下这个硬币时,才能从 i - coin 转移过来 if i >= coin: dp[i] = min(dp[i], dp[i - coin] + 1)
classSolution: defwordBreak(self, s: str, wordDict: List[str]) -> bool: # 将 wordDict 转为 set 提高查找效率 wordSet = set(wordDict) n = len(s)
# dp[i] 表示字符串 s 的前 i 个字符,是否可以由字典中的单词拼接出来 dp = [False] * (n + 1)
# 空串可以被成功拼接,作为后续转移的起点 dp[0] = True
# 枚举前缀长度 i,判断 s[0:i] 是否可以被拼接 for i inrange(1, n + 1): # 枚举最后一次切分的位置 j for j inrange(i): # 如果前 j 个字符可以被拼接,并且 s[j:i] 在字典中 # 那么前 i 个字符也可以被拼接 if dp[j] and s[j:i] in wordSet: dp[i] = True break
@cache defdfs(i, c): if i < 0: return1if c == 0else0 if c < nums[i]: return dfs(i - 1, c) # 求方案数所以用+而不是max return dfs(i - 1, c) + dfs(i - 1, c - nums[i])
classSolution: deflongestPalindrome(self, s: str) -> str: # 判断 s[left:right] 这一段是否是回文串 defis_palindrome(left, right): # 从两端向中间判断字符是否相等 while left < right: if s[left] != s[right]: returnFalse left += 1 right -= 1 returnTrue
n = len(s) # 记录最长回文子串长度 ans = 0 # 记录最长回文子串 res = ""
# 枚举所有子串的起点 for i inrange(n): # 枚举所有子串的终点 for j inrange(i, n): # 判断当前子串是否是回文串 if is_palindrome(i, j): length = j - i + 1 # 如果当前回文子串更长,则更新答案 if length > ans: ans = length res = s[i:j + 1]
# Your MinStack object will be instantiated and called as such: # obj = MinStack() # obj.push(val) # obj.pop() # param_3 = obj.top() # param_4 = obj.getMin()
有效的括号
给定一个只包括 '(',')','{','}','[',']' 的字符串 s ,判断字符串是否有效。
classSolution: defisValid(self, s: str) -> bool: iflen(s) %2: returnFalse mp = {')':'(', ']':'[', '}':'{'} st = [] for c in s: if c notin mp: # c是左括号 st.append(c) # 入栈 elifnot st or st.pop()!=mp[c]: returnFalse# 没有左括号或者不匹配 returnnot st # 栈内必须为空说明匹配完
classSolution: deflargestRectangleArea(self, heights: List[int]) -> int: n = len(heights) left = [-1] * n # 左边界数组,初始化为 -1 st = [] for i, h inenumerate(heights): # 找到左边第一个比当前柱子矮的柱子 while st and heights[st[-1]] >= h: st.pop() # 高的直接出栈 if st: # 如果栈不空,栈顶就是左边界索引 left[i] = st[-1] st.append(i)
right = [n] * n st.clear() for i inrange(n - 1, -1, -1): h = heights[i] while st and heights[st[-1]] >= h: st.pop() if st: right[i] = st[-1] st.append(i) ans = 0 for h, l, r inzip(heights, left, right): # 矩形宽度 = 右边界 - 左边界 - 1 ans = max(ans, h * (r - l - 1)) return ans
但其实发现,在找左边界的过程中,如果栈顶高度大于当前高度,那么对于栈顶,当前就是它的右边界
这样节省了一次循环
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
classSolution: deflargestRectangleArea(self, heights: List[int]) -> int: n = len(heights) left = [-1] * n # 左边界数组,初始化为 -1 right = [n] * n st = [] for i, h inenumerate(heights): # 找到左边第一个比当前柱子矮的柱子 while st and heights[st[-1]] >= h: right[st.pop()] = i if st: # 如果栈不空,栈顶就是左边界索引 left[i] = st[-1] st.append(i) ans = 0 for h, l, r inzip(heights, left, right): # 矩形宽度 = 右边界 - 左边界 - 1 ans = max(ans, h * (r - l - 1)) return ans
left = [x for x in nums if x > pivot] mid = [x for x in nums if x == pivot] right = [x for x in nums if x < pivot]
L, M = len(left), len(mid)
if k <= L: # 第 k 大在比 pivot 大的集合里 returnself.findKthLargest(left, k) elif k <= L + M: # 第 k 大正好落在等于 pivot 的集合里 return pivot else: # 第 k 大在比 pivot 小的集合里,注意要更新 k 的值 returnself.findKthLargest(right, k - L - M)
这样时间复杂度为O(n),空间复杂度为O(n)
如果用heapq,一个做法是直接用大根堆,找到前k个最大数
1 2 3 4 5
classSolution: deffindKthLargest(self, nums: List[int], k: int) -> int: # 使用 heapq.nlargest 找到前 k 大的元素 # 前 k 大元素中的最后一个就是第 k 大元素 return heapq.nlargest(k, nums)[-1]
时间复杂度为O(nlogk),空间复杂度为O(k)
但是这个方法太函数了,如果用小根堆
1 2 3 4 5 6 7 8 9 10
classSolution: deffindKthLargest(self, nums: List[int], k: int) -> int: heap = [] for num in nums: heapq.heappush(heap, num) # 超过k个就出堆 iflen(heap) > k: heapq.heappop(heap) # 最后堆顶就是第k大 return heap[0]
前 K 个高频元素
给你一个整数数组 nums 和一个整数 k ,请你返回其中出现频率前 k 高的元素。你可以按 任意顺序 返回答案。
classSolution: defmajorityElement(self, nums: List[int]) -> int: ans = hp = 0 for x in nums: if hp == 0: ans, hp = x, 1 else: hp += 1if x == ans else -1 return ans
相当于分为两类,非多数和多数
hp相当于累计值,多数肯定会>0
颜色分类
给定一个包含红色、白色和蓝色、共 n 个元素的数组 nums ,原地对它们进行排序,使得相同颜色的元素相邻,并按照红色、白色、蓝色顺序排列。
classSolution: defsortColors(self, nums: List[int]) -> None: """ Do not return anything, modify nums in-place instead. """ n = len(nums) left, i, right = 0, 0, n - 1 while i <= right: if nums[i] == 0: nums[left], nums[i] = num[i], nums[left] left += 1 i += 1 elif nums[i] == 1: i += 1 else: nums[i], nums[right] = nums[right], num[i] right -= 1




























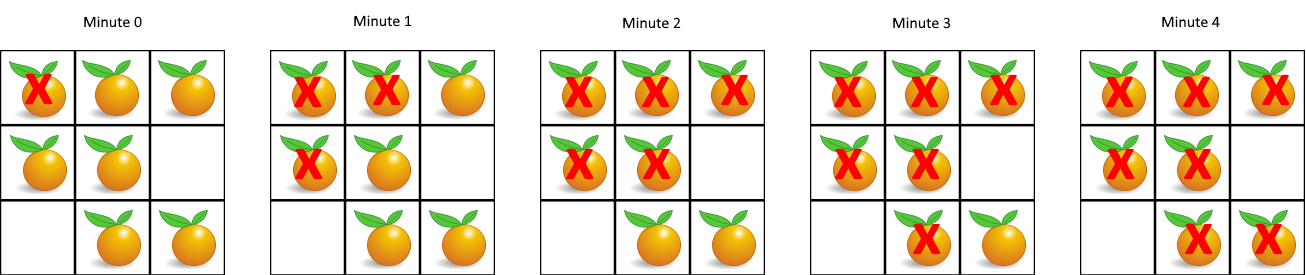




 (1).png)
.webp)

