算法大赛-天池大赛-阿里云的赛制
赛题理解 数据 该数据来自某新闻APP平台的用户交互数据,包括30万用户,近300万次点击,共36万多篇不同的新闻文章,同时每篇新闻文章有对应的embedding向量表示。为了保证比赛的公平性,从中抽取20万用户的点击日志数据作为训练集,5万用户的点击日志数据作为测试集A,5万用户的点击日志数据作为测试集B
数据表
train_click_log.csv:训练集用户点击日志
testA_click_log.csv:测试集用户点击日志
articles.csv:新闻文章信息数据表
articles_emb.csv:新闻文章embedding向量表示
sample_submit.csv:提交样例文件
字段表
Field Description
user_id
用户id
click_article_id
点击文章id
click_timestamp
点击时间戳
click_environment
点击环境
click_deviceGroup
点击设备组
click_os
点击操作系统
click_country
点击城市
click_region
点击地区
click_referrer_type
点击来源类型
article_id
文章id,与click_article_id相对应
category_id
文章类型id
created_at_ts
文章创建时间戳
words_count
文章字数
emb_1,emb_2,…,emb_249
文章embedding向量表示
评价方式 根据sample_submit.csv可知最后需要针对每个用户,给出五篇文章的推荐结果,按照点击概率从前往后排序
真实的每个用户最后一次点击的文章只会有一篇的真实答案,所以就看推荐的这五篇里面是否有命中真实答案的
提交结果:user1, article1, article2, article3, article4, article5
评价指标为MRR(Mean Reciprocal Rank),公式如下:
如果article2是用户点击的文章,则$s(\text{user},2)=1/2,s(\text{user},1,3,4,5)$都是0
如果都没命中,则$score(\text{user1})=0$
所以目标就是希望命中的结果尽量靠前,分数比较高
问题分析 给到的数据相当于是用户日志,不是那种特征+标签的数据
需要把问题变为一个监督学习的问题(特征+标签)
由于需要预测用户最后一次点击的新闻文章,简单来看是多分类问题,但是文章数有36万,过于庞大,需要将问题转化一下
转化为预测出某个用户最后一次对于某一篇文章会进行点击的概率,变为软分类,分类的标签就是用户是否会点击某篇文章
但接下来的问题是
如何转成监督学习问题?
训练集和测试集怎么制作?
能利用哪些特征?
可以尝试哪些模型?
数据分析 数据分析的价值主要在于熟悉了解整个数据集的基本情况包括每个文件里有哪些数据,具体的文件中的每个字段表示什么实际含义,以及数据集中特征之间的相关性,在推荐场景下主要就是分析用户本身的基本属性,文章基本属性,以及用户和文章交互的一些分布,这些都有利于后面的召回策略的选择,以及特征工程
导包 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 %matplotlib inline import gcimport osimport reimport sysimport warningsfrom pathlib import Pathimport matplotlib.pyplot as pltimport numpy as npimport pandas as pdimport seaborn as snsplt.rc('font' , size=13 ) warnings.filterwarnings("ignore" ) data_path = Path("tcdata" )
读取数据 1 2 3 4 5 6 7 8 trn_click = pd.read_csv(data_path / 'train_click_log.csv' ) item_df = pd.read_csv(data_path / 'articles.csv' ) item_df = item_df.rename(columns={'article_id' : 'click_article_id' }) item_emb_df = pd.read_csv(data_path / 'articles_emb.csv' ) tst_click = pd.read_csv(data_path / 'testA_click_log.csv' )
数据预处理 计算用户点击rank
1 2 3 4 5 trn_click['rank' ] = trn_click.groupby(['user_id' ])['click_timestamp' ].rank( ascending=False ).astype(int ) tst_click['rank' ] = tst_click.groupby(['user_id' ])['click_timestamp' ].rank(ascending=False ).astype(int )
为了统计点击次数,需要选择一列不会为NaN的,时间戳比较合适
1 2 3 trn_click['click_cnts' ] = trn_click.groupby(['user_id' ])['click_timestamp' ].transform('count' ) tst_click['click_cnts' ] = tst_click.groupby(['user_id' ])['click_timestamp' ].transform('count' )
数据浏览 训练集用户点击日志
将item_df中匹配click_article_id的信息合并
1 2 trn_click = trn_click.merge(item_df, how='left' , on=['click_article_id' ])
查看合并后的情况
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 <class 'pandas.core.frame.DataFrame'> RangeIndex: 1112623 entries, 0 to 1112622 Data columns (total 20 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 user_id 1112623 non-null int64 1 click_article_id 1112623 non-null int64 2 click_timestamp 1112623 non-null int64 3 click_environment 1112623 non-null int64 4 click_deviceGroup 1112623 non-null int64 5 click_os 1112623 non-null int64 6 click_country 1112623 non-null int64 7 click_region 1112623 non-null int64 8 click_referrer_type 1112623 non-null int64 9 rank 1112623 non-null int64 10 click_cnts 1112623 non-null int64 11 category_id_x 1112623 non-null int64 12 created_at_ts_x 1112623 non-null int64 13 words_count_x 1112623 non-null int64 14 category_id_y 1112623 non-null int64 15 created_at_ts_y 1112623 non-null int64 16 words_count_y 1112623 non-null int64 17 category_id 1112623 non-null int64 18 created_at_ts 1112623 non-null int64 19 words_count 1112623 non-null int64 dtypes: int64(20) memory usage: 169.8 MB
统计数据集中用户数量
1 trn_click.user_id.nunique()
查看最少点击量
1 trn_click.groupby('user_id' )['click_article_id' ].count().min ()
画直方图大体看一下基本的属性分布
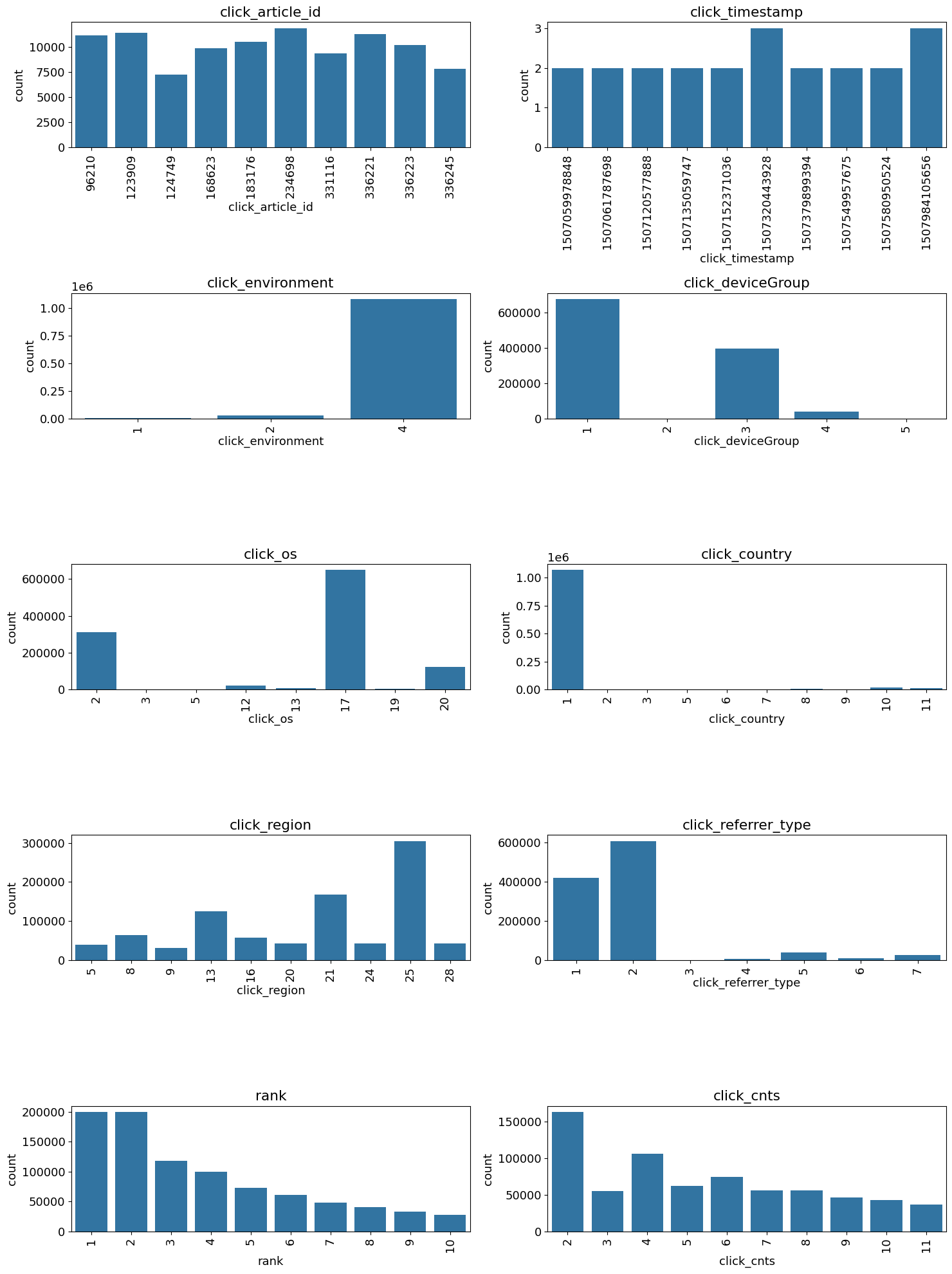
1 2 3 4 5 6 7 8 9 10 11 12 13 plt.figure(figsize=(15 , 20 )) i = 1 for col in ['click_article_id' , 'click_timestamp' , 'click_environment' , 'click_deviceGroup' , 'click_os' , 'click_country' , 'click_region' , 'click_referrer_type' , 'rank' , 'click_cnts' ]: plot_envs = plt.subplot(5 , 2 , i) i += 1 v = trn_click[col].value_counts().reset_index()[:10 ] fig = sns.barplot(x=v.iloc[:, 0 ], y=v.iloc[:, 1 ]) for item in fig.get_xticklabels(): item.set_rotation(90 ) plt.title(col) plt.tight_layout() plt.show()
.reset_index()会很常用,把当前索引还原成默认的 0,1,2,…,原索引可以选择保留成普通列
1 2 3 4 df = pd.DataFrame( {"name" : ["Alice" , "Bob" , "Charlie" ]}, index=["a" , "b" , "c" ] )
1 2 3 4 name a Alice b Bob c Charlie
1 2 3 4 index name 0 a Alice 1 b Bob 2 c Charlie
发生了两件事:
原来的索引 a b c 变成了一列(列名叫 index)
DataFrame 使用了新的默认整数索引 0,1,2
常跟在groupby后使用,使得groupby的列回到普通列,而不是成为索引
从点击时间clik_timestamp来看,分布较为平均,可不做特殊处理
从点击环境click_environment来看分布不均匀
1 2 3 v = trn_click['click_environment' ].value_counts().reset_index() v['ratio' ] = v.iloc[:, 1 ] / v.iloc[:, 1 ].sum () print (v.loc[:])
1 2 3 4 click_environment count ratio 0 4 1084627 0.974838 1 2 25894 0.023273 2 1 2102 0.001889
从点击设备组click_deviceGroup来看
1 2 3 v = trn_click['click_deviceGroup' ].value_counts().reset_index() v['ratio' ] = v.iloc[:, 1 ] / v.iloc[:, 1 ].sum () print (v.loc[:])
1 2 3 4 5 6 click_deviceGroup count ratio 0 1 678187 0.609539 1 3 395558 0.355518 2 4 38731 0.034811 3 5 141 0.000127 4 2 6 0.000005
训练集的用户ID由0~199999,而测试集A的用户ID由200000~249999
1 tst_click.user_id.nunique()
1 tst_click.groupby('user_id' )['click_article_id' ].count().min ()
注意,这里测试集有只点击过一次文章的用户,这里会有一些冷启动问题
新闻文章信息数据表
1 item_df['words_count' ].value_counts()
1 2 3 4 5 6 7 8 9 10 11 12 13 words_count 176 3485 182 3480 179 3463 178 3458 174 3456 ... 1040 1 871 1 627 1 473 1 841 1 Name: count, Length: 866, dtype: int64
统计主题数
1 print (item_df['category_id' ].nunique())
查看不同主体的文章数量
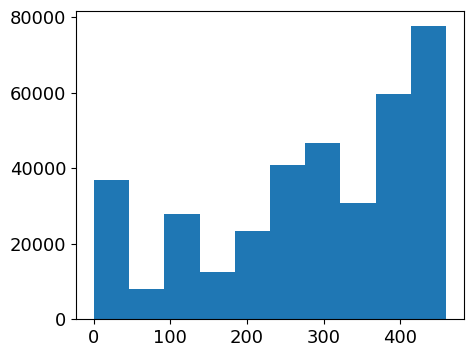
1 _ = item_df['category_id' ].hist(figsize=(5 , 4 ),grid=False )
一共有364047篇文章
最重要的语义向量给好
每篇文章独立向量,向量维度为251维
分析 用户重复点击
1 2 3 4 5 6 7 8 9 user_click_merge = pd.concat([trn_click, tst_click]) user_click_count = ( user_click_merge .groupby(['user_id' , 'click_article_id' ])['click_timestamp' ] .agg({'count' }) .reset_index() ) user_click_count.loc[:,'count' ].value_counts()
1 2 3 4 5 6 7 8 9 10 11 count 1 1605541 2 11621 3 422 4 77 5 26 6 12 10 4 7 3 13 1 Name: count, dtype: int64
agg 可以一次算多个指标
这里虽然只统计count一个量,理论上也可以写成count
在推荐 / CTR / 行为建模代码中,groupby + agg 是模板化写法 ,即使只算一个统计量,也会先用 agg
仅有极少数用户重复点击过某篇文章
用户点击环境变化分析
1 2 3 4 5 6 7 8 9 10 11 12 13 def plot_envs (df, cols, r, c, figsize=(8 , 4 ): plt.figure(figsize=figsize) i = 1 for col in cols: plt.subplot(r, c, i) i += 1 v = df[col].value_counts().reset_index() fig = sns.barplot(x=v.iloc[:, 0 ], y=v.iloc[:, 1 ]) for item in fig.get_xticklabels(): item.set_rotation(90 ) plt.title(col) plt.tight_layout() plt.show()
1 2 3 4 5 6 sample_user_ids = np.random.choice(tst_click['user_id' ].unique(), size=5 , replace=False ) sample_users = user_click_merge[user_click_merge['user_id' ].isin(sample_user_ids)] cols = ['click_environment' ,'click_deviceGroup' , 'click_os' , 'click_country' , 'click_region' ,'click_referrer_type' ] for _, user_df in sample_users.groupby('user_id' ): plot_envs(user_df, cols, 2 , 3 , figsize=(8 , 4 ))
根据结果图可以发现绝大多数数的用户的点击环境是比较固定的,可以基于这些环境的统计特征来代表该用户本身的属性
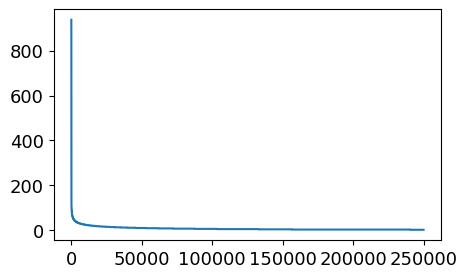
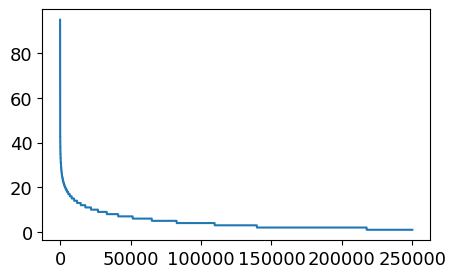
用户点击新闻数量的分布
1 2 3 4 5 6 7 8 9 user_click_item_count = sorted ( user_click_merge .groupby('user_id' )['click_article_id' ] .count() .value, reverse=True ) plt.figure(figsize=(5 , 3 )) _ = plt.plot(user_click_item_count)
可以根据用户的点击文章次数看出用户的活跃度
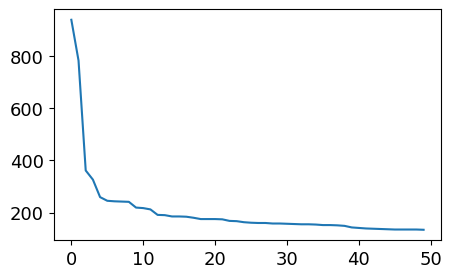
1 2 plt.figure(figsize=(5 , 3 )) _ = plt.plot(user_click_item_count[:50 ])
点击次数排前50的用户的点击次数都在100次以上
思路:可以定义点击次数大于等于100次的用户为活跃用户,这是一种简单的处理思路,判断用户活跃度,更加全面的是再结合上点击时间,会基于点击次数和点击时间两个方面来判断用户活跃度
1 2 plt.figure(figsize=(5 , 3 )) _ = plt.plot(user_click_item_count[150000 :170000 ])
点击数少于等于2的用户非常多,这些用户可以认为是非活跃用户
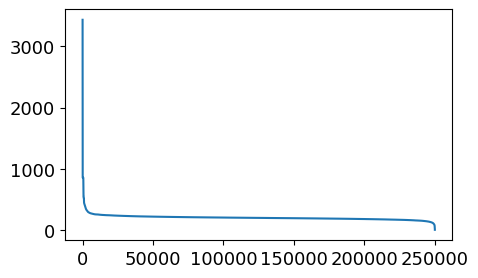
新闻点击次数分析
1 2 3 4 5 6 7 8 item_click_count = sorted ( user_click_merge .groupby('click_article_id' )['user_id' ] .count(), reverse=True ) plt.figure(figsize=(5 , 3 )) _ = plt.plot(item_click_count)
1 print (item_click_count[300 ],item_click_count[100 ], item_click_count[50 ])
1 2 plt.figure(figsize=(5 , 3 )) _ = plt.plot(item_click_count[10000 :])
可以定义点击次数超过一定量的为热门新闻,很多新闻只被点击过一两次,可以被定义为冷门新闻
新闻共现频次:两篇新闻连续出现的次数
统计“文章 i 后面紧跟文章 j”出现了多少次
1 2 3 4 5 6 7 8 9 10 11 12 13 14 tmp = user_click_merge.sort_values('click_timestamp' ) tmp['next_item' ] = ( tmp .groupby(['user_id' ])['click_article_id' ] .transform(lambda x: x.shift(-1 )) ) union_item = ( tmp .groupby(['click_article_id' , 'next_item' ])['click_timestamp' ] .agg({'count' }) .reset_index() .sort_values('count' , ascending=False ) ) union_item[['count' ]].describe()
统计 item → next_item 的共现次数
1 2 3 4 5 6 7 8 count,433596.000000 mean,3.184146 std,18.851689 min,1.000000 25%,1.000000 50%,1.000000 75%,2.000000 max,2202.000000
1 2 3 4 x = union_item['click_article_id' ] y = union_item['count' ] plt.figure(figsize=(5 , 3 )) _ = plt.scatter(x, y)
说明用户看的新闻,相关性是比较强的
用户点击的新闻类型的偏好
此特征可以用于度量用户的兴趣是否广泛
1 2 3 4 5 6 7 plt.figure(figsize=(5 , 3 )) _ = plt.plot(sorted ( user_click_merge .groupby('user_id' )['category_id' ] .nunique(), reverse=True ) )
有一小部分用户阅读类型是极其广泛的,大部分人都处在20个新闻类型以下
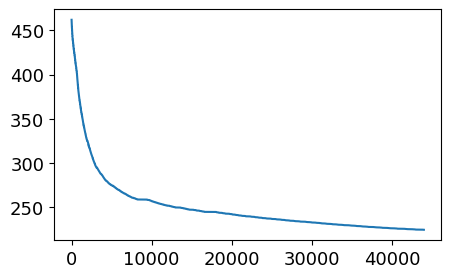
用户查看文章的长度的分布
1 2 3 4 5 6 7 plt.figure(figsize=(5 , 3 )) _ =plt.plot(sorted ( user_click_merge .groupby('user_id' )['words_count' ] .mean(), reverse=True ) )
从上图中可以发现有一小部分人看的文章平均词数非常高,也有一小部分人看的平均文章次数非常低
1 2 plt.figure(figsize=(5 , 3 )) _ = plt.plot(sorted (user_click_merge.groupby('user_id' )['words_count' ].mean(), reverse=True )[1000 :45000 ])
大部分人看的文章小于250字
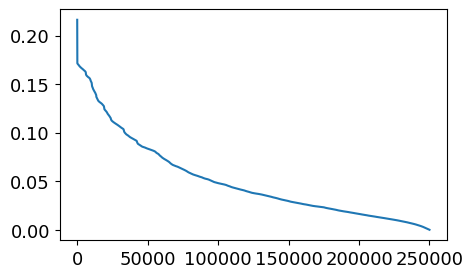
用户点击新闻的时间分析
1 2 3 4 5 6 7 8 9 10 11 12 13 from sklearn.preprocessing import MinMaxScalermm = MinMaxScaler() user_click_merge['click_timestamp' ] = mm.fit_transform( user_click_merge[['click_timestamp' ]] ) user_click_merge['created_at_ts' ] = mm.fit_transform( user_click_merge[['created_at_ts' ]] ) user_click_merge = user_click_merge.sort_values('click_timestamp' )
建立时间差函数
1 2 3 4 5 def mean_diff_time_func (df, col ): df = pd.DataFrame(df, columns=[col]) df['time_shift1' ] = df[col].shift(1 ).fillna(0 ) df['diff_time' ] = abs (df[col] - df['time_shift1' ]) return df['diff_time' ].mean()
1 2 3 4 5 6 mean_diff_click_time = ( user_click_merge .sort_values('click_timestamp' ) .groupby('user_id' )['click_timestamp' ] .apply(lambda x: mean_diff_time_func(x, 'click_timestamp' )) )
1 2 plt.figure(figsize=(5 , 3 )) _ = plt.plot(sorted (mean_diff_click_time.values, reverse=True ))
从上图可以发现不同用户点击文章的时间差是有差异的
1 2 3 4 5 mean_diff_created_time = ( user_click_merge .groupby('user_id' )[['created_at_ts' ]] .apply(mean_diff_time_func, col='created_at_ts' ) )
1 2 plt.figure(figsize=(5 , 3 )) _ = plt.plot(sorted (mean_diff_created_time.values, reverse=True ))
从图中可以发现用户先后点击文章,文章的创建时间也是有差异的
1 2 3 4 5 6 7 8 9 item_idx_2_rawid_dict = dict ( zip (item_emb_df['article_id' ], item_emb_df.index) ) del item_emb_df['article_id' ] item_emb_np = np.ascontiguousarray( item_emb_df.values, dtype=np.float32 )
1 2 3 4 5 sub_user_ids = np.random.choice(user_click_merge.user_id.unique(), size=15 , replace=False ) sub_user_info = user_click_merge[user_click_merge['user_id' ].isin(sub_user_ids)] sub_user_info.head()
1 2 3 4 5 6 7 8 9 def get_item_sim_list (df ): sim_list = [] item_list = df['click_article_id' ].values for i in range (0 , len (item_list)-1 ): emb1 = item_emb_np[item_idx_2_rawid_dict[item_list[i]]] emb2 = item_emb_np[item_idx_2_rawid_dict[item_list[i+1 ]]] sim_list.append(np.dot(emb1,emb2)/(np.linalg.norm(emb1)*(np.linalg.norm(emb2)))) sim_list.append(0 ) return sim_list
1 2 3 4 plt.figure(figsize=(5 , 3 )) for _, user_df in sub_user_info.groupby('user_id' ): item_sim_list = get_item_sim_list(user_df) plt.plot(item_sim_list)
从图中可以看出有些用户前后看的商品的相似度波动比较大,有些波动比较小,也是有一定的区分度的
总结
训练集和测试集的用户id没有重复,也就是测试集里面的用户没有模型是没有见过的
训练集中用户最少的点击文章数是2, 而测试集里面用户最少的点击文章数是1
用户对于文章存在重复点击的情况,但这个都存在于训练集里面
同一用户的点击环境存在不唯一的情况,后面做这部分特征的时候可以采用统计特征
用户点击文章的次数有很大的区分度,后面可以根据这个制作衡量用户活跃度的特征
文章被用户点击的次数也有很大的区分度,后面可以根据这个制作衡量文章热度的特征
用户看的新闻,相关性是比较强的,所以往往判断用户是否对某篇文章感兴趣的时候,在很大程度上会和历史点击过的文章有关
用户点击的文章字数有比较大的区别,这个可以反映用户对于文章字数的区别
用户点击过的文章主题也有很大的区别,这个可以反映用户的主题偏好
不同用户点击文章的时间差也会有所区别,这个可以反映用户对于文章时效性的偏好
Baseline baseline以ItemCF(基于物品的协同过滤)算法作为召回策略,这是工业界广泛使用的经典方法,具有可解释性强、效果稳定的特点
导包 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 import gcimport loggingimport mathimport osimport pickleimport randomimport timeimport warningsfrom collections import defaultdictfrom datetime import datetimefrom operator import itemgetterfrom pathlib import Pathlogger = logging.getLogger(__name__) warnings.filterwarnings('ignore' ) import numpy as npimport pandas as pdfrom tqdm import tqdmdata_path = Path("tcdata" ) save_path = Path("user_data" ) result_path = Path("prediction_result" ) if not os.path.exists(save_path): os.makedirs(save_path) if not os.path.exists(result_path): os.makedirs(result_path)
df节省内存函数 在不改变数据含义的前提下,把 DataFrame 的数值列转成“能用的最小 dtype”,从而节约内存
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 def reduce_mem (df ): starttime = time.time() numerics = ['int16' , 'int32' , 'int64' , 'float16' , 'float32' , 'float64' ] start_mem = df.memory_usage().sum () / 1024 **2 for col in df.columns: col_type = df[col].dtypes if col_type in numerics: c_min = df[col].min () c_max = df[col].max () if pd.isnull(c_min) or pd.isnull(c_max): continue if str (col_type)[:3 ] == 'int' : if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max : df[col] = df[col].astype(np.int8) elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max : df[col] = df[col].astype(np.int16) elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max : df[col] = df[col].astype(np.int32) elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max : df[col] = df[col].astype(np.int64) else : if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max : df[col] = df[col].astype(np.float16) elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max : df[col] = df[col].astype(np.float32) else : df[col] = df[col].astype(np.float64) end_mem = df.memory_usage().sum () / 1024 **2 print ( f'-- Mem. usage decreased to {end_mem:.2 f} Mb ' f'({100 *(start_mem-end_mem)/start_mem:.1 f} % reduction), ' f'time spend:{(time.time()-starttime)/60 :.2 f} min' ) return df
采样函数 按用户采样
1 2 3 4 5 6 7 8 9 10 11 12 13 14 def get_all_click_sample (data_path, sample_nums=10000 ): """ 训练集中采样一部分数据调试 data_path: 原数据的存储路径 sample_nums: 采样数目(这里由于机器的内存限制,可以采样用户做) """ all_click = pd.read_csv(data_path / 'train_click_log.csv' ) all_user_ids = all_click.user_id.unique() sample_user_ids = np.random.choice(all_user_ids, size=sample_nums, replace=False ) all_click = all_click[all_click['user_id' ].isin(sample_user_ids)] all_click = all_click.drop_duplicates((['user_id' , 'click_article_id' , 'click_timestamp' ])) return all_click
按行采样
1 2 3 4 5 6 7 8 9 10 11 def get_all_click_df (data_path, offline=True ): if offline: all_click = pd.read_csv(data_path / 'train_click_log.csv' )[:20000 ] else : trn_click = pd.read_csv(data_path / 'train_click_log.csv' )[:10000 ] tst_click = pd.read_csv(data_path / 'testA_click_log.csv' )[:10000 ] all_click = pd.concat([trn_click, tst_click]) all_click = all_click.drop_duplicates((['user_id' , 'click_article_id' , 'click_timestamp' ])).reset_index(drop=True ) return all_click
1 all_click_df = get_all_click_df(data_path, offline=False )
用户-文章-点击时间 获取 用户 - 文章 - 点击时间字典
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 def get_user_item_time (click_df ): click_df = click_df.sort_values('click_timestamp' ) def make_item_time_pair (df ): return list (zip (df['click_article_id' ], df['click_timestamp' ])) user_item_time_df = ( click_df.groupby('user_id' )[['click_article_id' , 'click_timestamp' ]] .apply(lambda x: make_item_time_pair(x)) .reset_index().rename(columns={0 : 'item_time_list' }) ) user_item_time_dict = dict ( zip ( user_item_time_df['user_id' ], user_item_time_df['item_time_list' ] ) ) return user_item_time_dict
Topk热门文章 获取点击最多的Topk个文章
1 2 3 4 def get_item_topk_click (click_df, k ): topk_click = click_df['click_article_id' ].value_counts().index[:k] return topk_click
ItemCF相似度 itemCF的物品相似度计算
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 def itemcf_sim (df ): """ 文章与文章之间的相似性矩阵计算 :param df: 数据表 :item_created_time_dict: 文章创建时间的字典 return : 文章与文章的相似性矩阵 """ user_item_time_dict = get_user_item_time(df) i2i_sim = {} item_cnt = defaultdict(int ) for user, item_time_list in tqdm( user_item_time_dict.items(), disable=not logger.isEnabledFor(logging.DEBUG) ): for i, i_click_time in item_time_list: item_cnt[i] += 1 i2i_sim.setdefault(i, {}) for j, j_click_time in item_time_list: if (i == j): continue i2i_sim[i].setdefault(j, 0 ) i2i_sim[i][j] += 1 / math.log(len (item_time_list) + 1 ) i2i_sim_ = i2i_sim.copy() for i, related_items in i2i_sim.items(): for j, wij in related_items.items(): i2i_sim_[i][j] = wij / math.sqrt(item_cnt[i] * item_cnt[j]) save_dir = save_path / 'tmp_data' save_dir.mkdir(parents=True , exist_ok=True ) pickle.dump( i2i_sim_, open (save_dir / 'itemcf_i2i_sim.pkl' , 'wb' ) ) return i2i_sim_ i2i_sim = itemcf_sim(all_click_df)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 i = 101,j=102 --- i2i_sim.setdefault(i, {}) i2i_sim = { 101: {} } --- i2i_sim[i].setdefault(j, 0) i2i_sim = { 101: { 102: Cij } }
itemCF推荐 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 def item_based_recommend (user_id, user_item_time_dict, i2i_sim, sim_item_topk, recall_item_num, item_topk_click ): """ 基于文章协同过滤的召回 :param user_id: 用户id :param user_item_time_dict: 字典, 根据点击时间获取用户的点击文章序列 {user1: {item1: time1, item2: time2..}...} :param i2i_sim: 字典,文章相似性矩阵 :param sim_item_topk: 整数, 选择与当前文章最相似的前k篇文章 :param recall_item_num: 整数, 最后的召回文章数量 :param item_topk_click: 列表,点击次数最多的文章列表,用户召回补全 return: 召回的文章列表 {item1:score1, item2: score2...} """ user_hist_items = user_item_time_dict[user_id] user_hist_item_set = {item for item, _ in user_hist_items} item_rank = {} for loc, (i, click_time) in enumerate (user_hist_items): for j, wij in sorted ( i2i_sim[i].items(), key=lambda x: x[1 ], reverse=True )[:sim_item_topk]: if j in user_hist_item_set: continue item_rank.setdefault(j, 0 ) item_rank[j] += wij if len (item_rank) < recall_item_num: for i, item in enumerate (item_topk_click): if item in item_rank: continue item_rank[item] = - i - 100 if len (item_rank) == recall_item_num: break item_rank = sorted ( item_rank.items(), key=lambda x: x[1 ], reverse=True )[:recall_item_num] return item_rank
给每个用户根据物品的协同过滤推荐文章
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 user_recall_items_dict = defaultdict(dict ) user_item_time_dict = get_user_item_time(all_click_df) i2i_sim = pickle.load(open (save_path / 'tmp_data/itemcf_i2i_sim.pkl' , 'rb' )) sim_item_topk = 10 recall_item_num = 10 item_topk_click = get_item_topk_click(all_click_df, k=50 ) for user in tqdm(all_click_df['user_id' ].unique(), disable=not logger.isEnabledFor(logging.DEBUG)): user_recall_items_dict[user] = item_based_recommend( user, user_item_time_dict, i2i_sim, sim_item_topk, recall_item_num, item_topk_click )
1 2 3 4 5 user_recall_items_dict = { user1: [(item1, score1)...], user2: [(item2, score2)...], ... }
召回字典转换成df
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 user_item_score_list = [] for user, items in tqdm(user_recall_items_dict.items(), disable=not logger.isEnabledFor(logging.DEBUG)): for item, score in items: user_item_score_list.append([user, item, score]) """ user_item_score_list = [ [user1, itemA, scoreA], [user1, itemB, scoreB], [user2, itemC, scoreC], ... ] """ recall_df = pd.DataFrame(user_item_score_list, columns=['user_id' , 'click_article_id' , 'pred_score' ]) recall_df.head()
提交函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 def submit (recall_df, topk=5 , model_name=None ): recall_df = recall_df.sort_values(by=['user_id' , 'pred_score' ]) recall_df['rank' ] = ( recall_df .groupby(['user_id' ])['pred_score' ] .rank(ascending=False , method='first' ) ) tmp = recall_df.groupby('user_id' ).apply(lambda x: x['rank' ].max ()) assert tmp.min () >= topk del recall_df['pred_score' ] submit = ( recall_df[recall_df['rank' ] <= topk] .set_index(['user_id' , 'rank' ]) .unstack(-1 ) .reset_index() ) submit.columns = [ int (col) if isinstance (col, int ) else col for col in submit.columns.droplevel(0 ) ] submit = submit.rename(columns={ '' : 'user_id' , 1 : 'article_1' , 2 : 'article_2' , 3 : 'article_3' , 4 : 'article_4' , 5 : 'article_5' }) save_name = save_path / ( model_name + '_' + datetime.today().strftime('%m-%d' ) + '.csv' ) submit.to_csv(save_name, index=False , header=True )
1 2 3 4 5 6 7 8 9 10 tst_click = pd.read_csv(data_path / 'testA_click_log.csv' ) tst_users = tst_click['user_id' ].unique() tst_recall = recall_df[recall_df['user_id' ].isin(tst_users)] submit(tst_recall, topk=5 , model_name='itemcf_baseline' )
这种简单的ItemCF提交得分为 0.1026
多路召回 多路召回策略是指使用多种不同的简单策略、特征或轻量模型,分别召回一部分候选集,再将这些候选集合并,供后续排序模型使用
这种策略本质上是在计算速度与召回率之间的权衡:
各类简单策略保证召回过程足够快
从不同角度设计的召回规则共同提升整体召回率,避免影响最终排序效果
在多路召回中,各个召回策略彼此独立,通常可以并行执行(如多线程),从而提升整体效率
需要注意的是,具体采用哪些召回策略高度依赖业务场景
不同任务对应不同的真实需求,因此召回规则也会有所差异,例如在新闻或视频推荐中,常见的召回方式包括:热门内容、导演召回、演员召回、近期上映、流行趋势、类型召回等
导包 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 import os, math, warnings, math, pickle, randomfrom pathlib import Pathfrom datetime import datetimefrom collections import defaultdictimport loggingwarnings.filterwarnings('ignore' ) os.environ['OMP_NUM_THREADS' ] = '1' logger = logging.getLogger(__name__) logger.setLevel(logging.INFO) import faiss import pandas as pdimport numpy as npfrom tqdm import tqdmfrom sklearn.preprocessing import MinMaxScalerfrom sklearn.preprocessing import LabelEncoderfrom sklearn.preprocessing import LabelEncoderfrom tensorflow.keras import backend as Kfrom tensorflow.keras.models import Modelfrom tensorflow.keras.preprocessing.sequence import pad_sequences
1 2 3 4 5 6 7 8 9 10 data_path = Path('tcdata' ) temp_path = Path("user_data/tmp_data" ) result_path = Path("prediction_result" ) if not os.path.exists(temp_path): os.makedirs(temp_path) if not os.path.exists(result_path): os.makedirs(result_path) metric_recall = False
读取数据 在推荐系统比赛中,数据读取通常分为三种模式,对应不同阶段与数据集使用方式
Debug 模式:用于快速搭建并跑通 baseline,验证整体代码流程是否正确
在该阶段一般从训练集中随机抽取一小部分样本(如 train_click_log_sample)进行调试,确保逻辑无误即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14 def get_all_click_sample (data_path, sample_nums=10000 ): """ 训练集中采样一部分数据调试 data_path: 原数据的存储路径 sample_nums: 采样数目(这里由于机器的内存限制,可以采样用户做) """ all_click = pd.read_csv(data_path / 'train_click_log.csv' ) all_user_ids = all_click.user_id.unique() sample_user_ids = np.random.choice(all_user_ids, size=sample_nums, replace=False ) all_click = all_click[all_click['user_id' ].isin(sample_user_ids)] all_click = all_click.drop_duplicates((['user_id' , 'click_article_id' , 'click_timestamp' ])) return all_click
线下验证模式:用于模型选择与超参数调优
此阶段加载完整训练集(train_click_log),并将其划分为训练集和验证集:训练集用于模型训练,验证集用于评估效果并调整模型与参数
线上模式:在 baseline 已跑通、模型与参数已确定后,进入最终预测阶段
该模式使用全量数据进行训练,即 train_click_log + test_click_log,对测试集生成预测结果并提交线上评测
1 2 3 4 5 6 7 8 9 10 11 12 13 14 def get_all_click_df (data_path, offline=True ): if offline: all_click = pd.read_csv(data_path / 'train_click_log.csv' ) else : trn_click = pd.read_csv(data_path / 'train_click_log.csv' ) tst_click = pd.read_csv(data_path / 'testA_click_log.csv' ) all_click = pd.concat([trn_click, tst_click]).reset_index(drop=True ) all_click = all_click.drop_duplicates((['user_id' , 'click_article_id' , 'click_timestamp' ])) return all_click
1 2 3 4 5 6 7 8 def get_item_info_df (data_path ): item_info_df = pd.read_csv(data_path / 'articles.csv' ) item_info_df = item_info_df.rename(columns={'article_id' : 'click_article_id' }) return item_info_df
1 2 3 4 5 6 7 8 9 10 11 12 13 14 def get_item_emb_dict (data_path ): item_emb_df = pd.read_csv(data_path / 'articles_emb.csv' ) item_emb_cols = [x for x in item_emb_df.columns if 'emb' in x] item_emb_np = np.ascontiguousarray(item_emb_df[item_emb_cols]) item_emb_np = item_emb_np / np.linalg.norm(item_emb_np, axis=1 , keepdims=True ) item_emb_dict = dict (zip (item_emb_df['article_id' ], item_emb_np)) pickle.dump(item_emb_dict, open (temp_path / 'item_content_emb.pkl' , 'wb' )) return item_emb_dict
1 2 3 4 5 6 7 8 9 max_min_scaler = lambda x : (x-np.min (x))/(np.max (x)-np.min (x)) all_click_df = get_all_click_sample(data_path) all_click_df['click_timestamp' ] = all_click_df[['click_timestamp' ]].apply(max_min_scaler)
1 item_info_df = get_item_info_df(data_path)
1 item_emb_dict = get_item_emb_dict(data_path)
工具函数 获取用户-文章-时间函数
常用于
基于序列的协同过滤
关联规则挖掘(A → B)
Item-Item 相似度
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 def get_user_item_time (click_df ): click_df = click_df.sort_values('click_timestamp' ) def make_item_time_pair (df ): return list (zip (df['click_article_id' ], df['click_timestamp' ])) user_item_time_df = ( click_df.groupby('user_id' )[['click_article_id' , 'click_timestamp' ]] .apply(lambda x: make_item_time_pair(x)) .reset_index().rename(columns={0 : 'item_time_list' }) ) user_item_time_dict = dict ( zip ( user_item_time_df['user_id' ], user_item_time_df['item_time_list' ] ) ) return user_item_time_dict
获取文章-用户-时间函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 def get_item_user_time_dict (click_df ): click_df = click_df.sort_values('click_timestamp' ) def make_user_time_pair (df ): return list (zip (df['user_id' ], df['click_timestamp' ])) item_user_time_df = ( click_df.groupby('click_article_id' )[['user_id' , 'click_timestamp' ]] .apply(lambda x: make_user_time_pair(x)) .reset_index() .rename(columns={0 : 'user_time_list' }) ) item_user_time_dict = dict ( zip ( item_user_time_df['click_article_id' ], item_user_time_df['user_time_list' ] ) ) return item_user_time_dict
获取历史和最后一次点击
在评估召回结果,特征工程和制作标签转成监督学习测试集时用到
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 def get_hist_and_last_click (all_click ): all_click = all_click.sort_values(by=['user_id' , 'click_timestamp' ]) click_last_df = all_click.groupby('user_id' ).tail(1 ) def hist_func (user_df ): if len (user_df) == 1 : return user_df else : return user_df[:-1 ] click_hist_df = ( all_click.groupby('user_id' ) .apply(hist_func) .reset_index(drop=True ) ) return click_hist_df, click_last_df
获取文章属性特征
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 def get_item_info_dict (item_info_df ): max_min_scaler = lambda x : (x-np.min (x))/(np.max (x)-np.min (x)) item_info_df['created_at_ts' ] = item_info_df[['created_at_ts' ]].apply(max_min_scaler) item_type_dict = dict ( zip (item_info_df['click_article_id' ], item_info_df['category_id' ]) ) item_words_dict = dict ( zip (item_info_df['click_article_id' ], item_info_df['words_count' ]) ) item_created_time_dict = dict ( zip (item_info_df['click_article_id' ], item_info_df['created_at_ts' ]) ) return item_type_dict, item_words_dict, item_created_time_dict
获取用户历史点击的文章信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 def get_user_hist_item_info_dict (all_click ): user_hist_item_typs = all_click.groupby('user_id' )['category_id' ].agg(set ).reset_index() user_hist_item_typs_dict = dict ( zip (user_hist_item_typs['user_id' ], user_hist_item_typs['category_id' ]) ) user_hist_item_ids_dict = all_click.groupby('user_id' )['click_article_id' ].agg(set ).reset_index() user_hist_item_ids_dict = dict ( zip (user_hist_item_ids_dict['user_id' ], user_hist_item_ids_dict['click_article_id' ]) ) user_hist_item_words = all_click.groupby('user_id' )['words_count' ].agg('mean' ).reset_index() user_hist_item_words_dict = dict ( zip (user_hist_item_words['user_id' ], user_hist_item_words['words_count' ]) ) all_click_ = all_click.sort_values('click_timestamp' ) user_last_item_created_time = (all_click_.groupby('user_id' )['created_at_ts' ] .apply(lambda x: x.iloc[-1 ]) .reset_index()) max_min_scaler = lambda x : (x-np.min (x))/(np.max (x)-np.min (x)) user_last_item_created_time['created_at_ts' ] = user_last_item_created_time[['created_at_ts' ]].apply(max_min_scaler) user_last_item_created_time_dict = dict ( zip (user_last_item_created_time['user_id' ], user_last_item_created_time['created_at_ts' ]) ) return user_hist_item_typs_dict, user_hist_item_ids_dict, user_hist_item_words_dict, user_last_item_created_time_dict
获取点击次数最多的Top-k个文章
1 2 3 4 def get_item_topk_click (click_df, k ): topk_click = click_df['click_article_id' ].value_counts().index[:k] return topk_click
定义多路召回字典 1 2 item_type_dict, item_words_dict, item_created_time_dict = get_item_info_dict(item_info_df)
1 2 3 4 5 6 user_multi_recall_dict = {'itemcf_sim_itemcf_recall' : {}, 'embedding_sim_item_recall' : {}, 'youtubednn_recall' : {}, 'youtubednn_usercf_recall' : {}, 'cold_start_recall' : {}}
1 2 3 trn_hist_click_df, trn_last_click_df = get_hist_and_last_click(all_click_df)
召回效果评估 需要对当前召回进行评价,因为召回的结果决定了最终排序的上限
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 def metrics_recall (user_recall_items_dict, trn_last_click_df, topk=5 ): last_click_item_dict = dict ( zip (trn_last_click_df['user_id' ], trn_last_click_df['click_article_id' ]) ) user_num = len (user_recall_items_dict) for k in range (10 , topk+1 , 10 ): hit_num = 0 for user, item_list in user_recall_items_dict.items(): tmp_recall_items = [x[0 ] for x in user_recall_items_dict[user][:k]] if last_click_item_dict[user] in set (tmp_recall_items): hit_num += 1 hit_rate = round (hit_num / user_num, 5 ) print ( ' topk: ' , k, ' : ' , 'hit_num: ' , hit_num, 'hit_rate: ' , hit_rate, 'user_num : ' , user_num )
1 2 3 4 user_recall_items_dict: { user_id: [(item_id1, score1), (item_id2, score2), ...] } # 已按 score 排好序,召回阶段的结果
计算相似性矩阵 通过协同过滤以及向量检索得到相似性矩阵
itemCF i2i_sim 借鉴KDD2020的去偏商品推荐,在计算item2item相似性矩阵时,使用关联规则,使得计算的文章的相似性还考虑到了
用户点击的时间权重
用户点击的顺序权重
文章创建的时间权重
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 def itemcf_sim (df, item_created_time_dict ): """ 根据用户的点击序列,计算“文章-文章”的相似度矩阵 :param df: 数据表 :item_created_time_dict: 文章创建时间的字典 return : 文章与文章的相似性矩阵 """ user_item_time_dict = get_user_item_time(df) i2i_sim = {} item_cnt = defaultdict(int ) for user, item_time_list in user_item_time_dict.items(): for loc1, (i, i_click_time) in enumerate (item_time_list): item_cnt[i] += 1 i2i_sim.setdefault(i, {}) for loc2, (j, j_click_time) in enumerate (item_time_list): if (i == j): continue i2i_sim[i].setdefault(j, 0 ) loc_alpha = 1.0 if loc2 > loc1 else 0.7 loc_weight = loc_alpha * (0.9 ** (np.abs (loc2 - loc1) - 1 )) click_time_weight = np.exp(0.7 ** np.abs (i_click_time - j_click_time)) created_time_weight = np.exp( 0.8 ** abs (item_created_time_dict[i] - item_created_time_dict[j]) ) i2i_sim[i][j] += ( loc_weight * click_time_weight * created_time_weight / math.log(len (item_time_list) + 1 ) ) i2i_sim_ = i2i_sim.copy() for i, related_items in i2i_sim.items(): for j, wij in related_items.items(): i2i_sim_[i][j] = wij / math.sqrt(item_cnt[i] * item_cnt[j]) pickle.dump(i2i_sim_, open (temp_path / 'itemcf_i2i_sim.pkl' , 'wb' )) return i2i_sim_
userCF u2u_sim 在计算用户之间的相似度的时候,也可以使用一些简单的关联规则,比如用户活跃度权重,这里将用户的点击次数作为用户活跃度的指标
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 def get_user_activate_degree_dict (all_click_df ): """ 用户活跃度计算 :param all_click_df: 数据表 return 用户用户活跃度字典 """ all_click_df_ = all_click_df.groupby('user_id' )['click_article_id' ].count().reset_index() mm = MinMaxScaler() all_click_df_['click_article_id' ] = mm.fit_transform(all_click_df_[['click_article_id' ]]) user_activate_degree_dict = dict (zip (all_click_df_['user_id' ], all_click_df_['click_article_id' ])) return user_activate_degree_dict
这个“活跃度分数”用来控制重度用户的影响力,用于共现统计/相似度计算时惩罚活跃用户
根据“哪些用户点过同一篇文章”,计算用户和用户之间的相似度矩阵
和 ItemCF 的差别只在“视角”
算法
共现的主体
ItemCF
同一个用户点过哪些 item
UserCF
同一个 item 被哪些用户点过
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 def usercf_sim (all_click_df, user_activate_degree_dict ): """ 用户相似性矩阵计算 :param all_click_df: 数据表 :param user_activate_degree_dict: 用户活跃度的字典 return 用户相似性矩阵 """ item_user_time_dict = get_item_user_time_dict(all_click_df) u2u_sim = {} user_cnt = defaultdict(int ) for item, user_time_list in tqdm(item_user_time_dict.items()): for u, click_time in user_time_list: user_cnt[u] += 1 u2u_sim.setdefault(u, {}) for v, click_time in user_time_list: u2u_sim[u].setdefault(v, 0 ) if u == v: continue activate_weight = 100 * 0.5 * ( user_activate_degree_dict[u] + user_activate_degree_dict[v] ) u2u_sim[u][v] += activate_weight / math.log(len (user_time_list) + 1 ) u2u_sim_ = u2u_sim.copy() for u, related_users in u2u_sim.items(): for v, wij in related_users.items(): u2u_sim_[u][v] = wij / math.sqrt(user_cnt[u] * user_cnt[v]) pickle.dump(u2u_sim_, open (temp_path / 'usercf_u2u_sim.pkl' , 'wb' )) return u2u_sim_
在这里时间戳没有被用到
UserCF 里常常不加时间,因为用户兴趣变化快,两个人在不同时间点看同一篇文章未必代表兴趣相似
ItemCF 更适合用序列 + 时间,因为它在考虑“用户看了 i 之后,会不会看 j?”
UserCF 只考虑“用户和谁兴趣像?”,是群体相似问题,时间信号没那么直接
item embedding sim 使用Embedding计算item之间的相似度是为了后续冷启动的时候可以获取未出现在点击数据中的文章
Faiss 是 Facebook AI 团队开源的一个用于向量聚类和相似性搜索 的库,底层由 C++ 实现,常用于推荐系统中的向量召回阶段
在向量召回中,常见形式包括 u2u、u2i 和 i2i。最直观的做法是通过两层循环遍历用户或物品向量,逐一计算相似度,但在用户和物品规模巨大的实际场景下,这种方式计算成本极高,几乎不可行
Faiss 通过高效的索引结构和近似搜索算法,加速从海量向量中找到与查询向量最相似的 Top-K 向量,从而显著提升召回效率
faiss查询的原理
faiss使用了PCA和PQ(Product quantization乘积量化)两种技术进行向量压缩和编码
PCA
主成分分析(Principal components analysis)是最重要的降维方法之一
目标是在尽量少损失信息的前提下,把高维数据投影到低维空间
保留前几个“主成分”相当于用更少的维度,描述数据中最重要的变化结构
最简单的例子,从2维降到1维,希望找到某一个维度方向,它可以代表这两个维度的数据
人眼可以看出$u_2$比$u_1$好,因为样本点在这个直线上的投影能尽可能的分开
标准 PCA 流程:
原始数据矩阵$X$
去均值(中心化) $X_c = X-\mu$
计算协方差矩阵
特征值分解 / SVD
按特征值从大到小排序
选前 k 个主成分
投影降维
将样本$x^{(i)}$投影到方向$w$上
用拉格朗日函数算$w$,$w$的约束是$w^Tw = 1$
$\Sigma$是对称正定矩阵,因此存在$d$个正交的特征向量
第一主成分就是最大方差方向,第二主成分是在正交约束下,取次大特征值的特征向量
这种用拉格朗日的解法为理论解法,但工程上几乎不用“直接特征分解协方差矩阵”,维度大的时候解复杂度太高,所以用SVD
右奇异向量就是主成分方向,奇异值平方对应方差大小
PQ编码 :通过把向量拆分到多个低维子空间并分别量化,用极少的存储成本近似向量距离,查询时通过查表加法完成距离计算
faiss使用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 def embdding_sim (click_df, item_emb_df, save_path, topk ): """ 基于内容的文章embedding相似性矩阵计算 :param click_df: 数据表 :param item_emb_df: 文章的embedding :param save_path: 保存路径 :patam topk: 找最相似的topk篇 return 文章相似性矩阵 思路: 对于每一篇文章, 基于embedding的相似性返回topk个与其最相似的文章,由于文章数量太多,使用faiss进行加速 """ item_idx_2_rawid_dict = dict (zip (item_emb_df.index, item_emb_df['article_id' ])) item_emb_cols = [x for x in item_emb_df.columns if 'emb' in x] item_emb_np = np.ascontiguousarray( item_emb_df[item_emb_cols].values, dtype=np.float32 ) item_emb_np = item_emb_np / np.linalg.norm(item_emb_np, axis=1 , keepdims=True ) item_index = faiss.IndexFlatIP(item_emb_np.shape[1 ]) item_index.add(item_emb_np) sim, idx = item_index.search(item_emb_np, topk) item_sim_dict = defaultdict(dict ) for target_idx, sim_value_list, rele_idx_list in tqdm( zip (range (len (item_emb_np)), sim, idx) ): target_raw_id = item_idx_2_rawid_dict[target_idx] for rele_idx, sim_value in zip (rele_idx_list[1 :], sim_value_list[1 :]): rele_raw_id = item_idx_2_rawid_dict[rele_idx] item_sim_dict[target_raw_id][rele_raw_id] = ( item_sim_dict.get(target_raw_id, {}).get(rele_raw_id, 0 ) + sim_value) pickle.dump(item_sim_dict, open (save_path / 'emb_i2i_sim.pkl' , 'wb' )) return item_sim_dict
1 2 3 item_emb_df = pd.read_csv(data_path / 'articles_emb.csv' ).sample(10000 , random_state=0 ).reset_index(drop=True ) emb_i2i_sim = embdding_sim(all_click_df, item_emb_df, temp_path, topk=10 )
召回 面对几十万文章、几十万用户的推荐问题,不可能对所有用户和所有文章做全量匹配,所以必须在召回阶段先用多种策略筛出一个小规模候选集,再交给后续排序模型处理
对每个用户,只考虑一小部分“有希望被点击的文章”,这一步就叫召回(Recall)
召回常用的策略:
基于文章的召回(i2i)
文章协同过滤(被同一用户点击)、文章 embedding(内容 / 表征向量)
不直接建模用户,只需要用户的历史点击文章,稳定、冷启动友好,
基于用户的召回(u2u)
用户协同过滤(点击行为重合)、用户 embedding(用户向量空间)
更个性化,对用户历史依赖更强,冷启动用户效果差
用户–文章直接匹配(u2i)
先学用户 embedding,再学文章 embedding,直接算用户向量和文章向量的相似度
双塔模型,YouTubeDNN召回
把用户和文章放进同一向量空间,工程复杂,但效果强
YoutubeDNN召回
重读Youtube深度学习推荐系统论文,字字珠玑,惊为神文 - 知乎 YouTube深度学习推荐系统的十大工程问题 - 知乎
用户塔 + 序列建模:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 def gen_data_set (data, negsample=0 ): data.sort_values("click_timestamp" , inplace=True ) item_ids = data['click_article_id' ].unique() train_set = [] test_set = [] for reviewerID, hist in tqdm(data.groupby('user_id' )): pos_list = hist['click_article_id' ].tolist() if negsample > 0 : candidate_set = list (set (item_ids) - set (pos_list)) neg_list = np.random.choice(candidate_set,size=len (pos_list)*negsample,replace=True ) if len (pos_list) == 1 : train_set.append((reviewerID, [pos_list[0 ]], pos_list[0 ],1 ,len (pos_list))) test_set.append((reviewerID, [pos_list[0 ]], pos_list[0 ],1 ,len (pos_list))) for i in range (1 , len (pos_list)): hist = pos_list[:i] if i != len (pos_list) - 1 : train_set.append((reviewerID, hist[::-1 ], pos_list[i], 1 , len (hist[::-1 ]))) for negi in range (negsample): train_set.append((reviewerID, hist[::-1 ], neg_list[i*negsample+negi], 0 ,len (hist[::-1 ]))) else : test_set.append((reviewerID, hist[::-1 ], pos_list[i],1 ,len (hist[::-1 ]))) random.shuffle(train_set) random.shuffle(test_set) return train_set, test_set def gen_model_input (train_set,user_profile,seq_max_len ): train_uid = np.array([line[0 ] for line in train_set]) train_seq = [line[1 ] for line in train_set] train_iid = np.array([line[2 ] for line in train_set]) train_label = np.array([line[3 ] for line in train_set]) train_hist_len = np.array([line[4 ] for line in train_set]) train_seq_pad = pad_sequences( train_seq, maxlen=seq_max_len, padding='post' , truncating='post' , value=0 ) train_model_input = { "user_id" : train_uid, "click_article_id" : train_iid, "hist_article_id" : train_seq_pad, "hist_len" : train_hist_len } return train_model_input, train_label
构建YouTube DNN双塔
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 import numpy as npimport tensorflow as tffrom tensorflow.keras.layers import Dense, Embedding, Inputfrom tensorflow.keras.models import Modelfrom tensorflow.keras.preprocessing.sequence import pad_sequencesfrom sklearn.preprocessing import LabelEncoderfrom collections import defaultdictimport faissdef build_youtubednn_model ( user_vocab_size, item_vocab_size, seq_len, emb_dim=16 , dnn_units=(32 , neg_sample=20 user_inp = Input(shape=(1 ,), name='user_id' ) item_inp = Input(shape=(1 ,), name='click_article_id' ) hist_inp = Input(shape=(seq_len,), name='hist_article_id' ) user_emb_layer = Embedding(user_vocab_size, emb_dim, name='user_emb' ) item_emb_layer = Embedding(item_vocab_size, emb_dim, name='item_emb' ) user_emb = tf.squeeze(user_emb_layer(user_inp), axis=1 ) item_emb = tf.squeeze(item_emb_layer(item_inp), axis=1 ) hist_emb = item_emb_layer(hist_inp) hist_mask = tf.cast(hist_inp > 0 , tf.float32) hist_len = tf.reduce_sum(hist_mask, axis=1 , keepdims=True ) hist_len = tf.maximum(hist_len, 1.0 ) hist_mask = tf.expand_dims(hist_mask, axis=-1 ) hist_sum = tf.reduce_sum(hist_emb * hist_mask, axis=1 ) hist_mean = hist_sum / hist_len user_vec = tf.concat([user_emb, hist_mean], axis=1 ) for i, u in enumerate (dnn_units): user_vec = Dense(u, activation='relu' , name=f'user_dnn_{i} ' )(user_vec) user_vec = Dense(emb_dim, activation=None , name='user_out' )(user_vec) user_vec = tf.nn.l2_normalize(user_vec, axis=1 ) loss = tf.nn.sampled_softmax_loss( weights=item_emb_layer.embeddings, biases=tf.zeros([item_vocab_size]), labels=item_inp, inputs=user_vec, num_sampled=neg_sample, num_classes=item_vocab_size ) model = Model( inputs=[user_inp, item_inp, hist_inp], outputs=user_vec ) model.add_loss(tf.reduce_mean(loss)) model.compile (optimizer=tf.keras.optimizers.Adam(1e-4 )) user_model = Model( inputs=[user_inp, hist_inp], outputs=user_vec ) return model, user_model, item_emb_layer
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 def youtubednn_u2i_dict (data, topk=20 ): """ - 标签/目标为正样本采样(sampled softmax 内部使用 item_id 作为 label) - 通过滑窗构造训练/测试样本,使用最近序列作为测试 - 历史序列长度固定为 SEQ_LEN,并做 post-padding - 训练完成后提取 user/item embedding,使用 FAISS 基于内积做 TopK 近邻召回 - 返回 {user_raw_id: [(item_raw_id, score), ...]} 的召回结果字典 """ seq_len = 30 emb_dim = 16 neg_sample = 20 dnn_units = [32 ] df = data.copy() user_encoder = LabelEncoder() item_encoder = LabelEncoder() df['user_id' ] = user_encoder.fit_transform(df['user_id' ]) df['click_article_id' ] = item_encoder.fit_transform(df['click_article_id' ]) user_cnt = df['user_id' ].nunique() item_cnt = df['click_article_id' ].nunique() train_set, test_set = gen_data_set(df, negsample=0 ) train_input = gen_model_input(train_set, seq_len) test_input = gen_model_input(test_set, seq_len) model, user_model, item_emb_layer = build_youtubednn_model( user_vocab_size=user_cnt + 1 , item_vocab_size=item_cnt + 1 , seq_len=seq_len, emb_dim=emb_dim, dnn_units=dnn_units, neg_sample=neg_sample ) model.fit( { "user_id" : train_input["user_id" ], "click_article_id" : train_input["click_article_id" ], "hist_article_id" : train_input["hist_article_id" ] }, batch_size=128 , epochs=5 , verbose=0 ) user_embs = user_model.predict( { "user_id" : test_input["user_id" ], "hist_article_id" : test_input["hist_article_id" ] }, batch_size=4096 , verbose=0 ) item_embs = item_emb_layer.embeddings.numpy() item_embs = item_embs / np.linalg.norm(item_embs, axis=1 , keepdims=True ) index = faiss.IndexFlatIP(emb_dim) index.add(item_embs.astype(np.float32)) sim, idx = index.search(user_embs.astype(np.float32), topk) user_raw = user_encoder.inverse_transform(test_input['user_id' ]) item_raw = item_encoder.inverse_transform( np.arange(item_embs.shape[0 ]) ) recall = defaultdict(list ) for u, sims, items in zip (user_raw, sim, idx): for i, s in zip (items[1 :], sims[1 :]): recall[u].append((item_raw[i], float (s))) return recall
1 2 3 4 5 6 7 8 if not metric_recall: user_multi_recall_dict['youtubednn_recall' ] = youtubednn_u2i_dict(all_click_df, topk=20 ) else : trn_hist_click_df, trn_last_click_df = get_hist_and_last_click(all_click_df) user_multi_recall_dict['youtubednn_recall' ] = youtubednn_u2i_dict(trn_hist_click_df, topk=20 ) metrics_recall(user_multi_recall_dict['youtubednn_recall' ], trn_last_click_df, topk=20 )
这里对齐torch
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 import torchimport torch.nn as nnimport torch.nn.functional as Fimport numpy as npimport faissfrom sklearn.preprocessing import LabelEncoderfrom collections import defaultdictclass YouTubeDNN (nn.Module): """ 对齐 TensorFlow 版本的 YouTubeDNN: - user embedding + hist mean pooling - DNN user tower - item embedding table - sampled softmax loss """ def __init__ ( self, user_vocab_size, item_vocab_size, seq_len, emb_dim=16 , dnn_units=(32 , neg_sample=20 ): super ().__init__() self .user_emb = nn.Embedding(user_vocab_size, emb_dim) self .item_emb = nn.Embedding(item_vocab_size, emb_dim) self .seq_len = seq_len self .neg_sample = neg_sample self .item_vocab_size = item_vocab_size dnn_layers = [] input_dim = emb_dim * 2 for u in dnn_units: dnn_layers.append(nn.Linear(input_dim, u)) dnn_layers.append(nn.ReLU()) input_dim = u dnn_layers.append(nn.Linear(input_dim, emb_dim)) self .user_dnn = nn.Sequential(*dnn_layers) def forward (self, user_id, hist_item, target_item ): """ 用于训练: - user_id: [B] - hist_item: [B, L] - target_item: [B] """ user_emb = self .user_emb(user_id) hist_emb = self .item_emb(hist_item) mask = (hist_item > 0 ).float () hist_len = mask.sum (dim=1 , keepdim=True ).clamp(min =1.0 ) hist_emb = hist_emb * mask.unsqueeze(-1 ) hist_mean = hist_emb.sum (dim=1 ) / hist_len user_vec = torch.cat([user_emb, hist_mean], dim=1 ) user_vec = self .user_dnn(user_vec) user_vec = F.normalize(user_vec, dim=1 ) loss = self .sampled_softmax_loss(user_vec, target_item) return loss def sampled_softmax_loss (self, user_vec, target_item ): """ 手写 sampled softmax(对齐 tf.nn.sampled_softmax_loss 语义) """ batch_size = user_vec.size(0 ) device = user_vec.device pos_emb = self .item_emb(target_item) pos_logits = torch.sum (user_vec * pos_emb, dim=1 , keepdim=True ) neg_items = torch.randint( low=0 , high=self .item_vocab_size, size=(batch_size, self .neg_sample), device=device ) neg_emb = self .item_emb(neg_items) neg_logits = torch.bmm( neg_emb, user_vec.unsqueeze(-1 ) ).squeeze(-1 ) logits = torch.cat([pos_logits, neg_logits], dim=1 ) labels = torch.zeros(batch_size, dtype=torch.long, device=device) loss = F.cross_entropy(logits, labels) return loss @torch.no_grad() def get_user_embedding (self, user_id, hist_item ): user_emb = self .user_emb(user_id) hist_emb = self .item_emb(hist_item) mask = (hist_item > 0 ).float () hist_len = mask.sum (dim=1 , keepdim=True ).clamp(min =1.0 ) hist_emb = hist_emb * mask.unsqueeze(-1 ) hist_mean = hist_emb.sum (dim=1 ) / hist_len user_vec = torch.cat([user_emb, hist_mean], dim=1 ) user_vec = self .user_dnn(user_vec) return F.normalize(user_vec, dim=1 ) @torch.no_grad() def get_item_embedding (self ): emb = self .item_emb.weight return F.normalize(emb, dim=1 )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 def youtubednn_u2i_dict_torch (data, topk=20 ): """ PyTorch 版本 YouTubeDNN 召回(语义对齐 TF 版) """ seq_len = 30 emb_dim = 16 neg_sample = 20 dnn_units = (32 ,) df = data.copy() user_encoder = LabelEncoder() item_encoder = LabelEncoder() df['user_id' ] = user_encoder.fit_transform(df['user_id' ]) df['click_article_id' ] = item_encoder.fit_transform(df['click_article_id' ]) user_cnt = df['user_id' ].nunique() item_cnt = df['click_article_id' ].nunique() train_set, test_set = gen_data_set(df, negsample=0 ) train_input = gen_model_input(train_set, seq_len) test_input = gen_model_input(test_set, seq_len) device = torch.device("cuda" if torch.cuda.is_available() else "cpu" ) model = YouTubeDNN( user_vocab_size=user_cnt + 1 , item_vocab_size=item_cnt + 1 , seq_len=seq_len, emb_dim=emb_dim, dnn_units=dnn_units, neg_sample=neg_sample ).to(device) optimizer = torch.optim.Adam(model.parameters(), lr=1e-4 ) model.train() batch_size = 128 n = len (train_input['user_id' ]) for epoch in range (5 ): perm = np.random.permutation(n) for i in range (0 , n, batch_size): idx = perm[i:i+batch_size] user_id = torch.tensor(train_input['user_id' ][idx], device=device) hist_item = torch.tensor(train_input['hist_article_id' ][idx], device=device) target_item = torch.tensor(train_input['click_article_id' ][idx], device=device) loss = model(user_id, hist_item, target_item) optimizer.zero_grad() loss.backward() optimizer.step() model.eval () user_embs = model.get_user_embedding( torch.tensor(test_input['user_id' ], device=device), torch.tensor(test_input['hist_article_id' ], device=device) ).cpu().numpy() item_embs = model.get_item_embedding().cpu().numpy() index = faiss.IndexFlatIP(emb_dim) index.add(item_embs.astype(np.float32)) sim, idx = index.search(user_embs.astype(np.float32), topk) user_raw = user_encoder.inverse_transform(test_input['user_id' ]) item_raw = item_encoder.inverse_transform(np.arange(item_embs.shape[0 ])) recall = defaultdict(list ) for u, sims, items in zip (user_raw, sim, idx): for i, s in zip (items[1 :], sims[1 :]): recall[u].append((item_raw[i], float (s))) return recall
itemCF召回 已经通过协同过滤,Embedding检索的方式得到了文章的相似度矩阵
使用协同过滤的思想,给用户召回与其历史文章相似的文章
在召回的时候,使用关联规则
考虑相似文章与历史点击文章顺序的权重
考虑文章创建时间的权重,也就是考虑相似文章与历史点击文章创建时间差的权重
考虑文章内容相似度权重
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 def item_based_recommend (user_id, user_item_time_dict, i2i_sim, sim_item_topk, recall_item_num, item_topk_click, item_created_time_dict, emb_i2i_sim ): """ 基于文章协同过滤的召回 :param user_id: 用户id :param user_item_time_dict: 字典, 根据点击时间获取用户的点击文章序列 {user1: {item1: time1, item2: time2..}...} :param i2i_sim: 字典,文章相似性矩阵 :param sim_item_topk: 整数, 选择与当前文章最相似的前k篇文章 :param recall_item_num: 整数, 最后的召回文章数量 :param item_topk_click: 列表,点击次数最多的文章列表,用户召回补全 :param emb_i2i_sim: 字典基于内容embedding算的文章相似矩阵 return: 召回的文章列表 {item1:score1, item2: score2...} """ user_hist_items = user_item_time_dict[user_id] item_rank = {} for loc, (i, click_time) in enumerate (user_hist_items): for j, wij in sorted (i2i_sim[i].items(), key=lambda x: x[1 ], reverse=True )[:sim_item_topk]: if j in user_hist_items: continue created_time_weight = np.exp( 0.8 ** np.abs ( item_created_time_dict[i] - item_created_time_dict[j] ) ) loc_weight = (0.9 ** (len (user_hist_items) - loc)) content_weight = 1.0 if emb_i2i_sim.get(i, {}).get(j, None ) is not None : content_weight += emb_i2i_sim[i][j] if emb_i2i_sim.get(j, {}).get(i, None ) is not None : content_weight += emb_i2i_sim[j][i] item_rank.setdefault(j, 0 ) item_rank[j] += ( created_time_weight * loc_weight * content_weight * wij ) if len (item_rank) < recall_item_num: for i, item in enumerate (item_topk_click): if item in item_rank.items(): continue item_rank[item] = - i - 100 if len (item_rank) == recall_item_num: break item_rank = sorted ( item_rank.items(), key=lambda x: x[1 ], reverse=True )[:recall_item_num] return item_rank
itemCF sim召回
在这里i2i_sim是共现统计
主辅分离(行为相似度 × (1 + 内容相似度))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 if metric_recall: trn_hist_click_df, trn_last_click_df = get_hist_and_last_click(all_click_df) else : trn_hist_click_df = all_click_df user_recall_items_dict = defaultdict(dict ) user_item_time_dict = get_user_item_time(trn_hist_click_df) i2i_sim = pickle.load(open (temp_path / 'itemcf_i2i_sim.pkl' , 'rb' )) emb_i2i_sim = pickle.load(open (temp_path / 'emb_i2i_sim.pkl' , 'rb' )) sim_item_topk = 20 recall_item_num = 10 item_topk_click = get_item_topk_click(trn_hist_click_df, k=50 ) for user in tqdm(trn_hist_click_df['user_id' ].unique()): user_recall_items_dict[user] = item_based_recommend( user, user_item_time_dict, i2i_sim, sim_item_topk, recall_item_num, item_topk_click, item_created_time_dict, emb_i2i_sim) user_multi_recall_dict['itemcf_sim_itemcf_recall' ] = user_recall_items_dict pickle.dump(user_multi_recall_dict['itemcf_sim_itemcf_recall' ], open (temp_path / 'itemcf_recall_dict.pkl' , 'wb' )) if metric_recall: metrics_recall(user_multi_recall_dict['itemcf_sim_itemcf_recall' ], trn_last_click_df, topk=recall_item_num)
1 topk: 10 : hit_num: 6112 hit_rate: 0.6112 user_num : 10000
embedding sim 召回
在这里i2i_sim == emb_i2i_sim
主辅叠加 embedding 相似度 × (1 + embedding 相似度)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 if metric_recall: trn_hist_click_df, trn_last_click_df = get_hist_and_last_click(all_click_df) else : trn_hist_click_df = all_click_df user_recall_items_dict = defaultdict(dict ) user_item_time_dict = get_user_item_time(trn_hist_click_df) i2i_sim = pickle.load(open (temp_path / 'emb_i2i_sim.pkl' ,'rb' )) sim_item_topk = 20 recall_item_num = 10 item_topk_click = get_item_topk_click(trn_hist_click_df, k=50 ) for user in tqdm(trn_hist_click_df['user_id' ].unique()): user_recall_items_dict[user] = item_based_recommend( user, user_item_time_dict, i2i_sim, sim_item_topk, recall_item_num, item_topk_click, item_created_time_dict, emb_i2i_sim) user_multi_recall_dict['embedding_sim_item_recall' ] = user_recall_items_dict pickle.dump(user_multi_recall_dict['embedding_sim_item_recall' ], open (temp_path / 'embedding_sim_item_recall.pkl' , 'wb' )) if metric_recall: metrics_recall(user_multi_recall_dict['embedding_sim_item_recall' ], trn_last_click_df, topk=recall_item_num)
1 topk: 10 : hit_num: 781 hit_rate: 0.0781 user_num : 10000
userCF召回 
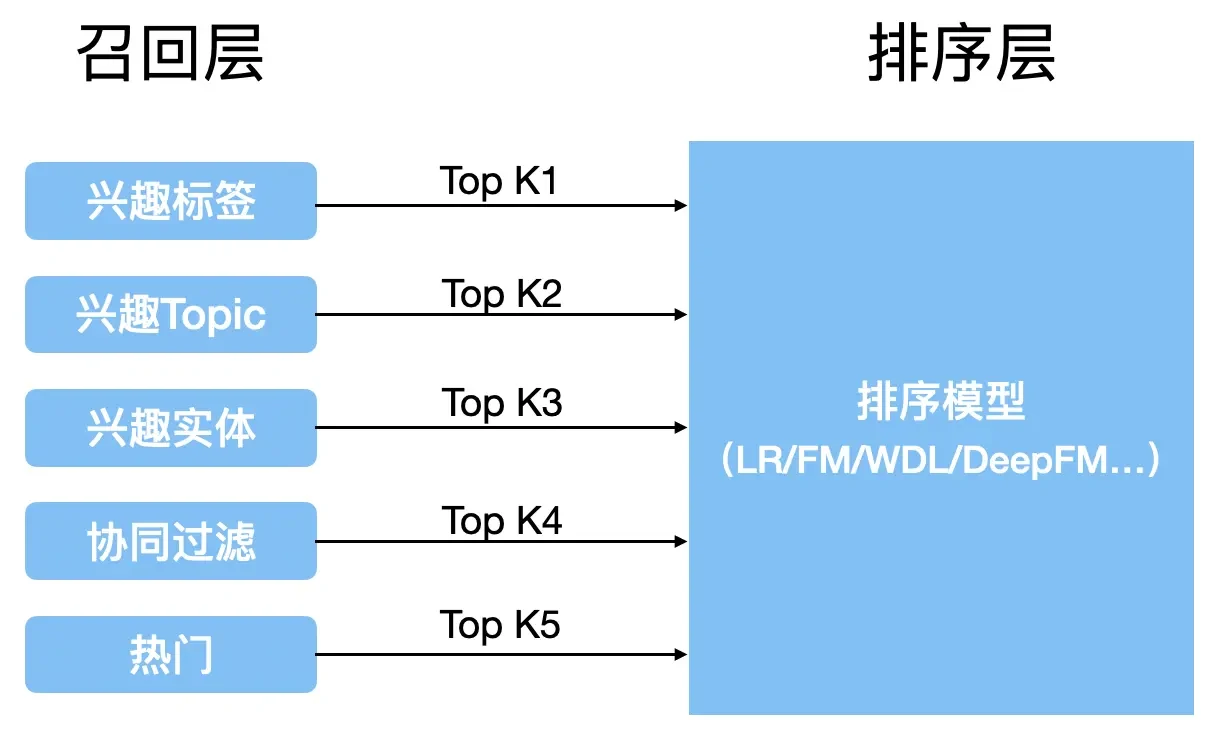
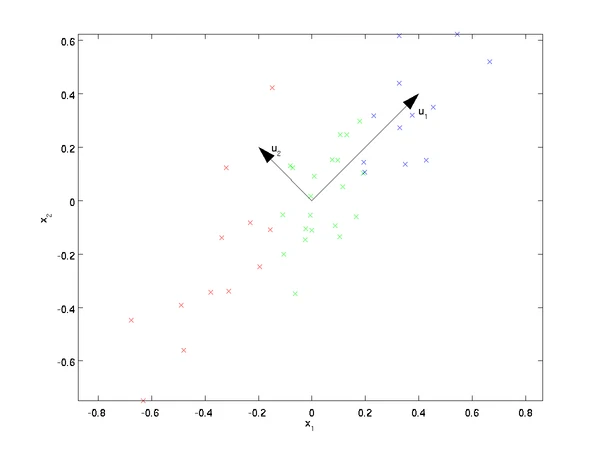

 (1).png)
.webp)

