
卷积神经网络
图像数据的每个样本都由一个二维像素网格组成,每个像素可能是一个或者多个数值,取决于是黑白还是彩色图像
之前仅仅通过将图像数据展平成一维向量而忽略了每个图像的空间结构信息,再将数据送入一个全连接的多层感知机中。因为这些网络特征元素的顺序是不变的,因此最优的结果是利用先验知识,即利用相近像素之间的相互关联性,从图像数据中学习得到有效的模型
**卷积神经网络(convolutional neural network,CNN)**是一类强大的、为处理图像数据而设计的神经网络,基于卷积神经网络架构的模型在计算机视觉领域中已经占主导地位
卷积神经网络需要的参数少于全连接架构的网络,而且卷积也很容易用GPU并行计算
从全连接层到卷积
MLP适合处理那些“每个特征相互独立且无结构”的任务
对于表格数据,特征之间的关系往往复杂且难以事先定义,模式可能来源于任意特征的非线性交互,此时多层感知机可能是最好的选择
然而对于高维感知数据,这种缺少结构的网络可能会变得不实用
不变性
假设想从一张图片中找到某个物体,合理的假设是:无论哪种方法找到这个物体,都应该和物体的位置无关
卷积神经网络(CNN)正是把这种“空间不变性”的思想系统化的模型。它能在不同位置识别出相同的特征,通过共享参数与局部感知实现高效的特征学习,用更少的参数捕捉图像中的关键信息
特性总结:
- 平移不变性(translation invariance):不管检测对象出现在图像中的哪个位置,神经网络的前面几层应该对相同的图像区域具有相似的反应,即为“平移不变性”
- 局部性(locality):神经网络的前面几层应该只探索输入图像中的局部区域,而不过度在意图像中相隔较远区域的关系,这就是“局部性”原则
多层感知机的限制
存在两个核心问题:
- 参数太多,容易过拟合且计算开销大
- 忽略空间结构,无法捕捉局部特征的空间关系(例如邻近像素常常相关)
卷积
为了使每个隐藏神经元都能接收到每个输入像素的信息,将参数从权重矩阵替换为四阶权重张量$\mathsf{W}$,假设$\mathbf{U}$包含偏置参数,可以将全连接层形式化地表示为
$$
\begin{split}\begin{aligned} \mathbf H_{i, j} &= \mathbf U_{i, j} + \sum_k \sum_l\mathsf W_{i, j, k, l} \mathbf X_{k, l}\\ &= \mathbf U_{i, j} + \sum_a \sum_b \mathsf V_{i, j, a, b} \mathbf X_{i+a, j+b}.\end{aligned}\end{split}
$$
从$\mathsf{W}$到$\mathsf{V}$的转换只是形式上的转换,使$k = i+a, l = j+b$
把输入索引从绝对坐标$(k, l)$改写成相对输出位置的位移$(a,b)$
$$
\mathsf V_{i, j, a, b} = \mathsf W_{i, j, i+a, j+b}
$$
索引$a$和$b$通过在正偏移和负偏移之间移动覆盖了整个图像
平移不变性
检测对象在输入$\mathbf{X}$中的平移,应该仅导致隐藏表示$\mathbf{H}$中的平移,$\mathsf{V,U}$实际上不依赖于$(i, j)$的值
可以简化$\mathbf{H}$为
$$
\mathbf H_{i, j} = u + \sum_a\sum_b \mathbf V_{a, b} \mathbf X_{i+a, j+b}.
$$
这就是卷积(convolution)
使用系数$\mathbf V_{a, b}$对位置$(i, j)$附近的像素$(i+a, j+b)$进行加权得到$[\mathbf{H}]_{i, j}$
卷积核在图像上滑动(平移),每个位置使用同一组参数,实现权重共享(weight sharing),保证了平移不变性
局部性
不应偏离到距$(i,j)$很远的地方,在$\mid a\mid > \Delta , \mid b\mid >\Delta $的范围之外可以设置$[\mathbf{V}]_{a, b} = 0$
可以将$\mathbf H_{i, j}$重写为
$$
\mathbf H_{i, j} = u + \sum_{a = -\Delta}^{\Delta} \sum_{b = -\Delta}^{\Delta} \mathbf V_{a, b} \mathbf X_{i+a, j+b}.
$$
这就是卷积层(convolutional layer)
在深度学习研究社区中$\mathbf{V}$被称为卷积核(convolution kernel)或者滤波器(filter)
亦或简单地称之为该卷积层的权重,通常该权重是可学习的参数
思考题
为什么平移不变性可能也不是好主意呢?
平移不变性关注的是特征是否出现过,而不在意它在图像中的位置
在图像分类等任务中非常有效,但当任务依赖精确位置或结构时,这种假设反而会成为限制
理想的做法不是彻底放弃平移不变性,而是在保持共享的同时引入位置信息,让模型既高效又具空间感知
图像卷积
互相关
在数学中,两个离散二维张量之间的“卷积”被定义为
$$
(f * g)(i, j) = \sum_a\sum_b f(a, b) g(i-a, j-b).
$$
会发现其实数学定义是需要翻转的,但是刚刚写的并没有翻转,深度学习里所谓的“卷积”其实严格意义上是互相关(cross-correlation),它没有翻转卷积核,只是把核在输入上滑动求和
但人们习惯仍称它为“卷积层”,因为计算形式和思想完全一致
因为卷积核的宽度和高度大于1,而卷积核只与图像中每个大小完全适合的位置进行互相关运算,设输入大小为$n_h \times n_w$,卷积核大小$k_h \times k_w$,则输出大小
$$
\color{purple} (n_h-k_h+1) \times (n_w-k_w+1).
$$
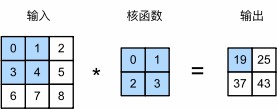
在corr2d函数中实现如上过程,该函数接受输入张量X和卷积核张量K,并返回输出张量Y
1 | def corr2d(X, K): #@save |
测试函数:
1 | X = torch.tensor([[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]]) |
1 | tensor([[19., 25.], |
卷积层
卷积层对输入和卷积核权重进行互相关运算,并在添加标量偏置之后产生输出
卷积层中的两个被训练的参数是卷积核权重和标量偏置,也需要随机初始化
基于上面定义的corr2d函数实现二维卷积层,在__init__构造函数中,将weight和bias声明为两个模型参数,前向传播函数调用corr2d函数并添加偏置
1 | class Conv2D(nn.Module): |
目标的边缘检测
通过找到像素变化的位置,来检测图像中不同颜色的边缘
构造一个6×8像素的黑白图像,中间四列为黑色(0),周围为白色(1)
1 | X = torch.ones((6, 8)) |
1 | tensor([[1., 1., 0., 0., 0., 0., 1., 1.], |
构造一个高度为1、宽度为2的卷积核$K$,当进行互相关运算时,如果水平相邻的两元素相同,则输出为零,否则输出为非零
1 | K = torch.tensor([[1.0, -1.0]]) |
1 | Y = corr2d(X, K) |
1 | tensor([[ 0., 1., 0., 0., 0., -1., 0.], |
发现输出很明显的边缘信息
现在将输入的二维图像转置,再进行如上的互相关运算
1 | corr2d(X.t(), K) |
1 | tensor([[0., 0., 0., 0., 0.], |
之前检测到的垂直边缘消失了,这个卷积核K只可以检测垂直边缘,无法检测水平边缘
学习卷积核
如果只需寻找黑白边缘,那么[-1,1]边缘检测器足以,当有了更复杂数值的卷积核,或者连续的卷积层时,不可能手动设计滤波器
所以就要进入迭代学习的部分
先讲一下nn.Conv2d
1 | nn.Conv2d( |
1 | # 构造一个二维卷积层,它具有1个输出通道和形状为(1,2)的卷积核 |
1 | epoch 2, loss 7.668 |
在10次迭代之后,误差已经降到足够低
查看学习获得的卷积核权重张量
1 | conv2d.weight.data.reshape(1,2) |
1 | tensor([[ 0.9800, -0.9914]]) |
和之前定义的基本接近
特征映射和感受野
输出的卷积层有时被称为特征映射(feature map),因为它可以被视为一个输入映射到下一层的空间维度的转换器
在卷积神经网络中,对于某一层的任意元素$x$,其**感受野(receptive field)**是指在前向传播期间可能影响$x$计算的所有元素(来自所有先前层)
感受野可能大于输入的实际大小,在多层卷积网络中,感受野会随着层数的增加逐渐变大
若每一层卷积核大小为 2×2,第一层输出的每个元素受输入4个像素影响,再经过一层卷积后,感受野不仅是输入的4个元素,还有最初的9个输入
因此随着卷积层的叠加,感受野不断扩大,使网络能够捕捉更高层次、更全局的特征
填充和步幅
填充
在应用了连续的卷积之后,最终得到的输出远小于输入大小,如此一来原始图像的边界丢失了许多有用信息,**填充(padding)**是解决此问题最有效的方法
在输入图像的边界填充元素(通常填充元素是0)

通常对称填充,填充大小为$p_h=k_h-1$和$p_w=k_w-1$,使得输入和输出具有相同高度和宽度
卷积神经网络中卷积核的高度和宽度通常为奇数,例如1、3、5或7,选择奇数的好处是,保持空间维度的同时,在对称方向上填充的行数相同
1 | # 为了方便起见,定义了一个计算卷积层的函数 |
当卷积核高度宽度相同时,填充大小相同;如果不同,需要填充不同的高度和宽度
padding大小为(kernel_size-1)/2
1 | X = torch.rand(size=(8, 8)) |
1 | torch.Size([8, 8]) |
步幅
在计算互相关时,卷积窗口从输入张量的左上角开始,向下、向右滑动
默认每次滑动一个元素,但有时候为了高效计算或是缩减采样次数,卷积窗口可以跳过中间位置,每次滑动多个元素
将每次滑动元素的数量称为步幅(stride)
垂直步幅为3,水平步幅为2的二维互相关运算
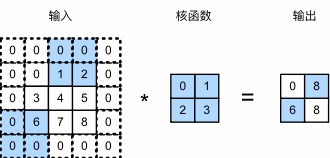
当垂直步幅为$s_h$,水平步幅为$s_w$时,输出形状为
$$
\color{purple}H = \lfloor \frac{n_h-k_h+p_h}{s_h}+1\rfloor \qquad W=\lfloor\frac{n_w-k_w+p_w}{s_w}+1\rfloor.
$$
公式通用的,计算池化后的尺寸也是用这个
如果设置了填充大小为$p_h=k_h-1$和$p_w=k_w-1$,简化为
$$
H = \lfloor \frac{n_h-1}{s_h}+1\rfloor \qquad W=\lfloor\frac{n_w-1}{s_w}+1\rfloor.
$$
如果输入的高度和宽度可以被垂直和水平步幅整除,则输出形状将为$(n_h/s_h) \times (n_w/s_w)$
将高度和宽度的步幅设置为2,从而将输入的高度和宽度减半
1 | conv2d = nn.Conv2d(1, 1, kernel_size=3, padding=1, stride=2) |
1 | torch.Size([4, 4]) |
多输入多输出
多输入通道
假设输入的通道数为$c_i$,那么卷积核的输入通道数也需要为$c_i$
$c_i=1$时可以把卷积核看作形状为$k_h\times k_w$的二维张量
$c_i>1$时可以得到形状为$c_i\times k_h\times k_w$的卷积核,对每个通道输入的二维张量和卷积核的二维张量进行互相关运算,再对通道求和得到二维张量
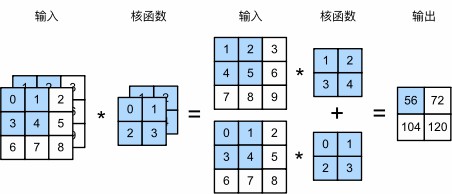
函数实现
1 | def corr2d_multi_in(X, K): |
求和代表融合后的特征,综合了所有输入通道在同一空间位置的响应
1 | X = torch.tensor([[[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]], |
1 | tensor([[ 56., 72.], |
多输出通道
随着神经网络层数的加深,常会增加输出通道的维数,通过减少空间分辨率以获得更大的通道深度
即可以将每个通道看作对不同特征的响应,每个通道并不是彼此独立而是协同优化的
为了获得多个通道的输出,可以为每个输出通道创建一个形状为$c_i\times k_h\times k_w$的卷积核张量,卷积核的形状是$\color{red}c_o\times c_i\times k_h\times k_w$,输出$c_o$个通道
实现一个计算多个通道的输出的互相关函数
1 | def corr2d_multi_in_out(X, K): |
1 | K = torch.stack((K, K + 1, K + 2), 0) |
1 | tensor([[[ 56., 72.], |
现在的输出包含3个通道,第一个通道的结果与先前结果一致
1×1卷积层
看起来似乎没有多大意义,但是可以进行通道计算,输出中的每个元素都是从输入图像中同一位置的元素的线性组合
可以将1×1卷积层看作在每个像素位置应用的全连接层
以$c_i$个输入值转换为$c_o$个输出值

使用全连接层实现1×1卷积,需要对输入和输出形状进行调整
1 | def corr2d_multi_in_out_1x1(X, K): |
1×1 卷积没有空间移动,只在通道维度上“融合信息”
小结
- 多输入多输出通道可以用来扩展卷积层的模型
- 当以每像素为基础应用时,1×1卷积层相当于全连接层
- 1×1卷积层通常用于调整网络层的通道数量和控制模型复杂性
思考题
假设有两个卷积核大小分别为$k_1$和$k_2$(中间没有非线性激活函数)
两次卷积等价于一次卷积,因为卷积运算有结合律
等效卷积核大小为$k_1+k_2-1$
但一个大卷积 ≠ 任意两次小卷积,除非满足特殊可分离条件
假设输入为$c_i\times h\times w$,卷积核大小为$c_o\times c_i\times k_h\times k_w$,填充为$(p_h, p_w)$,步幅为$(s_h, s_w)$
前向传播的计算成本(乘法和加法)是多少?
输出空间尺寸
$$
H = \lfloor \frac{n_h-k_h+p_h}{s_h}+1\rfloor \qquad W=\lfloor\frac{n_w-k_w+p_w}{s_w}+1\rfloor.
$$
每个输出像素是一个长度为$c_i k_hk_w$的点积
$$
\mathrm{Multi_{fwd}} = c_oHW(c_ik_h k_w) \qquad \mathrm{Add_{fwd}}= c_oHW(c_i k_hk_w-1)
$$
若有偏置,再为每个输出像素加一次加法总复杂度$O(c_oHWc_ik_hk_w)$
内存占用是多少?
必须同时驻留输入、权重、输出(以及可选偏置)
$$
Mem_{fwd}= c_ihw+ c_oc_ik_hk_w +c_oHW +(c_o)
$$
再乘以dtype大小,$c_o$为偏置大小
如果将输入通道和输出通道的数量加倍,计算数量会增加多少?把填充数量翻一番会怎么样?
计算量增加4倍;
填充增大导致输出空间略变大,对计算量的影响相对较小、近似线性
汇聚/池化
当处理图像时,希望逐渐降低隐藏表示的空间分辨率、聚集信息,这样随着在神经网络中层叠的上升,每个神经元对其敏感的感受野(输入)就越大
机器学习任务通常会跟全局图像的问题有关,所以最后一层的神经元应该对整个输入全局敏感
通过逐渐聚合信息,生成越来越粗糙的映射,最终实现学习全局表示的目标,同时将卷积图层的所有优势保留在中间层
汇聚(pooling)层的目的:
- 降低卷积层对位置的敏感性
- 降低对空间降采样表示的敏感性
汇聚层做的就是池化操作
汇聚层
汇聚层与卷积层相似,都通过一个固定大小的窗口在输入上滑动,并根据步幅计算输出
但汇聚层执行的是确定性的运算,没有可学习的参数,通常取窗口内元素的最大值或平均值,即最大汇聚(max pooling)和平均汇聚(average pooling)

几乎不会用到最小池化,因为最小池化往往保留噪声或背景,不太有助于学习
Softmax软最大在性能上并没有带来显著提升,难以抵消其计算代价,并不常用
在下面的pool2d函数实现汇聚层的前向传播
1 | def pool2d(X, pool_size, mode='max'): |
其实和互相关很像,但是没用到卷积核
输入张量X,验证二维最大汇聚层的输出
1 | X = torch.tensor([[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]]) |
1 | tensor([[4., 5.], |
填充和步幅
与卷积层一样,汇聚层也可以改变输出形状,仍然通过填充和步幅来实现
首先构造了一个输入张量X,它有四个维度,其中样本数和通道数都是1
1 | X = torch.arange(16, dtype=torch.float32).reshape((1, 1, 4, 4)) |
1 | tensor([[[[ 0., 1., 2., 3.], |
默认情况下,深度学习框架中的步幅与汇聚窗口的大小相同
1 | torch.nn.MaxPool2d( |
1 | pool2d = nn.MaxPool2d(3) |
1 | tensor([[[[10.]]]]) |
填充和步幅可以手动设定
1 | pool2d = nn.MaxPool2d((2, 3), stride=(2, 3), padding=(0, 1)) |
1 | tensor([[[[ 5., 7.], |
多个通道
在处理多通道输入数据时,汇聚层在每个输入通道上单独运算,而不是像卷积层一样在通道上对输入进行汇总,所以汇聚层的输出通道数与输入通道数相同
将在通道维度上连结张量X和X + 1,以构建具有2个通道的输入
1 | X1 = torch.cat((X, X + 1), 1) |
汇聚后输出通道的数量仍然是2
1 | tensor([[[[ 5., 7.], |
小结
- 对于给定输入元素,最大汇聚层会输出该窗口内的最大值,平均汇聚层会输出该窗口内的平均值
- 汇聚层的主要优点之一是减轻卷积层对位置的过度敏感
- 可以指定汇聚层的填充和步幅
- 使用最大汇聚层以及大于1的步幅,可减少空间维度(如高度和宽度)
- 汇聚层的输出通道数与输入通道数相同
卷积神经网络(LeNet)
LeNet,它是最早发布的卷积神经网络之一,发布时的目的是识别图像(LeCun et al., 1998)中的手写数字
LeNet取得了与**支持向量机(support vector machines)**性能相媲美的成果,成为监督学习的主流方法,被广泛用于自动取款机(ATM)机中,帮助识别处理支票的数字
网络结构
总体来看,LeNet(LeNet-5)由两个部分组成:
- 卷积编码器:由两个卷积层组成
- 全连接层稠密块:由三个全连接层组成
稠密块可以理解为一组顺序堆叠的全连接层 + 激活函数
和后面的DenseNet没有关系
该架构如图所示
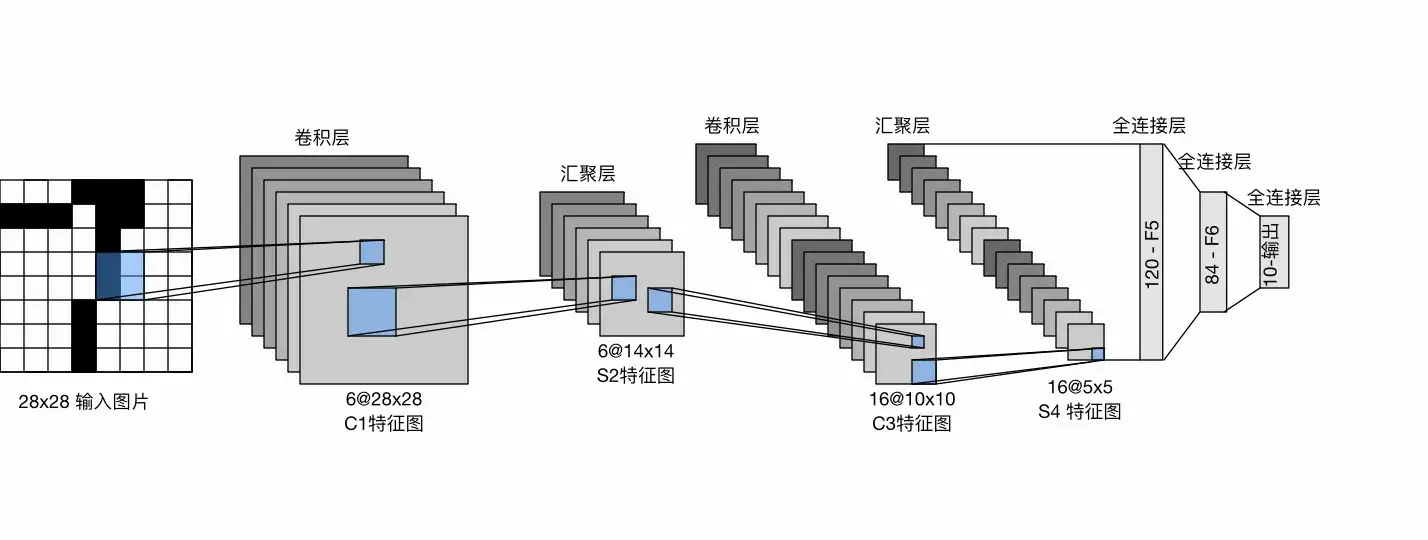
每个卷积块由一个使用 5×5 卷积核的卷积层、一个 sigmoid 激活函数和一个平均汇聚层组成
虽然 ReLU 激活函数和最大汇聚层在性能上更高效,但它们当时尚未被提出
这些层将输入映射到多个二维特征输出,并在提取特征的同时逐步增加通道数
第一层卷积输出6个通道,第二层卷积输出16个通道
汇聚操作采用2×2窗口,通过空间下采样使特征图尺寸缩小4倍,减少计算量
在将卷积块的输出输入至稠密块前,必须在小批量中展平每个样本,将样本从四维张量(批量、通道、高、宽)转换为二维矩阵,第一维表示样本索引,第二维为该样本的平面向量表示
LeNet的稠密块有三个全连接层,分别有120、84和10个输出
由于任务是手写数字识别,最终的 10 维输出对应于 10 个数字类别
只需要实例化一个Sequential块并将需要的层连接在一起就能实现LeNet-5
因为用的MNIST,所以不是原版32×32,所以在第一层卷积的时候加入padding让28->32
1 | net = nn.Sequential( |
对原始模型做了一点小改动,去掉了最后一层的高斯激活
将一个大小为28×28的单通道(黑白)图像通过LeNet,并在每一层打印输出的形状
1 | X = torch.rand(size=(1, 1, 28, 28), dtype=torch.float32) |
1 | Layer Output shape |
模型训练
看看LeNet在Fashion-MNIST数据集上的表现
1 | batch_size = 256 |
虽然卷积神经网络的参数较少,但与深度的多层感知机相比,它们的计算成本仍然很高,因为每个参数都参与更多的乘法,通过使用GPU,可以用它加快训练
由于完整的数据集位于内存中,因此在模型使用GPU计算数据集之前,需要将其复制到显存中
对之前evaluate_accuracy函数进行轻微的修改
1 | def evaluate_accuracy_gpu(net, data_iter, device=None): #@save |
训练函数也有所变化,进行正向和反向传播之前,需要将每一小批量数据移动到指定的设备(例如GPU)上
训练函数train_ch6也类似于之前定义的train_ch3,这里用到sigmoid激活所以使用Xavier初始化模型参数,使用交叉熵损失函数和小批量随机梯度下降
1 | #@save |
1 | lr, num_epochs = 0.9, 10 |
1 | training on cpu |
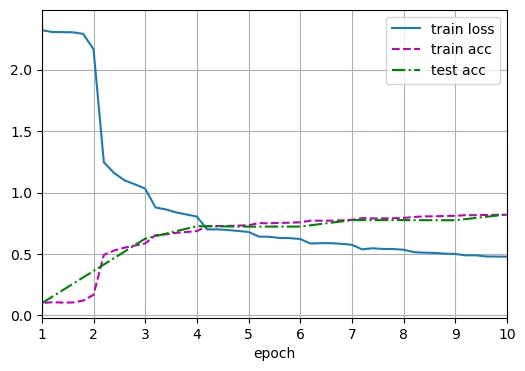
1 | loss 0.478, train acc 0.819, test acc 0.821 |
模型升级
如果想将ReLU和最大汇聚层加入其中优化,需要对结构进行一些修改
1 | net = nn.Sequential( |
同时初始化函数要修改为Kaiming初始化
1 | def init_weights(m): |
因为ReLU的梯度比较大,所以学习率不能那么大,设为0.15
1 | lr, num_epochs = 0.15, 10 |
1 | training on cpu |
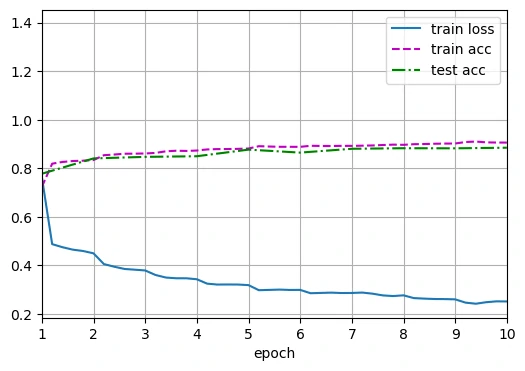
1 | loss 0.252, train acc 0.906, test acc 0.885 |
可以看到准确率得到了大幅提升
思考题
将平均汇聚层替换为最大汇聚层,会发生什么?
平均汇聚会把特征“柔化”,而最大汇聚让模型更关注最突出的区域,所以输出特征图会更稀疏、更“尖锐”
只有最大值那一个像素会收到梯度更新,对于 LeNet 这种浅层网络来说,可能导致部分通道几乎不更新,梯度传播变稀疏
收敛速度可能更快,但不稳定
需要对应更换激活函数为ReLU才能发货最大汇聚层的优势
改进LeNet
方面 原始设计 改进方向 激活函数 Sigmoid 改为 ReLU 池化方式 AvgPool 改为 MaxPool 卷积核大小 5×5 改为 3×3(更细特征) 输出通道数 6, 16 增大为 16, 32 卷积层数量 2 层 增加到 3 层 全连接层数量 3 层 减少到 2 层或用 Dropout 防过拟合 初始化 Xavier 改为 Kaiming 优化器 SGD(lr=0.9) 改为 Adam(lr=1e-3) 训练轮数 10 增加到 15~20 基本就能实现91–93%的准确率
深度卷积神经网络(AlexNet)
在LeNet提出后,卷积神经网络在计算机视觉和机器学习领域中很有名气,但卷积神经网络并没有主导这些领域
因为虽然LeNet在小数据集上取得了很好的效果,但是在更大、更真实的数据集上训练卷积神经网络的性能和可行性还有待研究
学习表征
在2012年前,图像特征都是机械地计算出来的,SIFT(Lowe, 2004)、SURF(Bay et al., 2006)、HOG(定向梯度直方图)(Dalal and Triggs, 2005)、bags of visual words等特征提取方法占据了主导地位
另一组研究人员提出特征应由模型自动学习,并通过多层神经网络在不同层次提取抽象特征,在视觉任务中,底层可学习边缘、颜色和纹理等基本特征
这一思想在AlexNet(Krizhevsky et al., 2012) 中得到突破性验证
AlexNet 的底层卷积核学到的模式与传统图像滤波器极为相似

AlexNet的更高层建立在这些底层表示的基础上,以表示更大的特征
深度卷积神经网络的突破出现在2012年,突破可归因于两个关键因素
- 数据:10年以后数据集的规模快速扩大(ImageNet)
- 硬件:GPU并行计算实现
网络结构
AlexNet和LeNet的架构非常相似,左图为LeNet结构,右图为AlexNet结构
图中AlexNet结构去除了原文需要两个小型GPU同时运算的设计特点
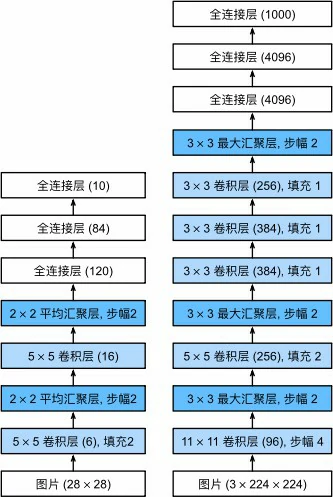
AlexNet和LeNet的设计理念非常相似,但也存在显著差异
AlexNet比相对LeNet要深得多,由八层组成:五个卷积层、两个全连接隐藏层和一个全连接输出层
AlexNet使用ReLU而不是sigmoid作为其激活函数
计算更简单,不需要幂次计算,并且避免出现初始化异常导致梯度消失的情况
第一层卷积窗口的形状是11×11,这是因为ImageNet的图片是要比MNIST长宽大10倍以上,需要一个更大的卷积窗口来捕获目标;第二层的形状为5×5,其余卷积层为3×3
在第一层、第二层和第五层卷积层之后,加入窗口形状为3×3,步幅为2的最大汇聚层,并且卷积通道数是LeNet的10倍
在最后一个卷积层后有两个全连接层,分别有4096个输出,这两个巨大的全连接层拥有将近1GB的模型参数
早期GPU内存有限,原版AlexNet采用了双数据流设计,使得每个GPU负责存储和计算模型的一半参数,现在很少需要跨GPU分解模型了
AlexNet通过暂退法控制全连接层的模型复杂度,而LeNet只使用了权重衰减
为了进一步扩充数据,AlexNet在训练时增加了大量的图像增强数据,如翻转、裁切和变色,这使得模型更健壮,更大的样本量有效地减少了过拟合(以下代码中没有体现)
实例化一个Sequential块并将需要的层连接在一起实现AlexNet
1 | net = nn.Sequential( |
构造一个高度和宽度都为224的单通道数据,来观察每一层输出的形状
1 | X = torch.randn(1, 1, 224, 224) |
1 | Layer Output Shape |
模型训练
原文中AlexNet是在ImageNet上进行训练的,但在这里使用的是Fashion-MNIST数据集
因为即使在现代GPU上,训练ImageNet模型,同时使其收敛可能需要数小时或数天的时间
将AlexNet直接应用于Fashion-MNIST会出现一个问题,Fashion-MNIST图像的分辨率低于ImageNet图像,在这里为了方便使用直接将MNIST图像resize到224×224(通常这不是一个明智的做法)
1 | batch_size = 128 |
现在AlexNet可以开始被训练了,这里的主要变化是使用更小的学习速率训练,这是因为网络更深更广、图像分辨率更高,训练卷积神经网络就更昂贵
1 | lr, num_epochs = 0.01, 10 |
到这里cpu烤不动了,得换到有GPU的电脑来跑了
1 | training on cuda:0 |

1 | loss 0.275, train acc 0.900, test acc 0.899 |
小结
- AlexNet的架构与LeNet相似,但使用了更多的卷积层和更多的参数来拟合大规模的ImageNet数据集
- AlexNet已经被更有效的架构所超越,但它是从浅层网络到深层网络的关键一步
- Dropout、ReLU和预处理是提升计算机视觉任务性能的其他关键步骤
思考题
分析了AlexNet的计算性能
在AlexNet中主要是哪部分占用显存?
特征图(feature maps) 和 模型参数(parameters)
模型参数:
类型 层定义参数 输出尺寸 模型参数 Conv1 11×11, stride=4, padding=2, out_channels=96 55×55×96 34,944 MaxPool 3×3, stride=2 27×27×96 Conv2 5×5, padding=2, out_channels=256 27×27×256 614,656 MaxPool 3×3, stride=2 13×13×256 Conv3 3×3, out_channels=384 13×13×384 885,120 Conv4 3×3, out_channels=384 13×13×384 1,327,488 Conv5 3×3, out_channels=256 13×13×256 884,992 MaxPool 3×3, stride=2 6×6×256 FC1 4096 neurons - 37,752,832 FC2 4096 neurons - 16,781,312 FC3 1000 neurons (ImageNet classes) - 4,097,000 卷积层的参数计算公式
$$
\mathrm{Params} = (k_h\times k_w\times C_{in})\times C_{out}+C_{out}
$$模块 参数数量 卷积层 ≈ 3.75 M 全连接层 ≈ 58.6 M 总计 ≈ 62.3 M 在AlexNet中主要是哪部分需要更多的计算?
中间到后期的卷积层
对于一个卷积层,乘加次数为
$$
\mathrm{MAC_s} = K_h\times K_w\times C_{in}\times H_{out}\times W_{out}\times C_{out}
$$层 输入尺寸 卷积核 输出通道 输出尺寸 乘加次数 Conv1 3×224×224 11×11 96 54×54 105M Conv2 96×54×54 5×5 256 26×26 448M Conv3 256×26×26 3×3 384 26×26 298M Conv4 384×26×26 3×3 384 26×26 447M Conv5 384×26×26 3×3 256 26×26 298M 全连接层虽然参数多(占了 90% 的参数量),但计算量反而较小
业内有两种说法:
- FLOPs 把一次乘加算 2 次运算
- MACs 把一次乘加算 1 次运算
使用块的网络(VGG)
虽然AlexNet证明深层神经网络卓有成效,但它没有提供一个通用的模板
与芯片设计中工程师从放置晶体管到逻辑元件再到逻辑块的过程类似,神经网络架构的设计也逐渐变得更加抽象,开始从单个神经元的角度思考问题,发展到整个层,现在又转向块,重复层的模式
使用块的想法首先出现在牛津大学的视觉几何组的VGG网络中
VGG块
经典卷积神经网络的基本组成部分是下面的这个序列:
- 带填充以保持分辨率的卷积层
- 非线性激活函数,如ReLU
- 汇聚层,如最大汇聚层
而一个VGG块与之类似,由一系列卷积层组成,后面再加上用于空间下采样的最大汇聚层
在最初的VGG论文中(Simonyan and Zisserman, 2014)使用了带有3×3卷积核,填充为1(保持高度和宽度)的卷积层和2×2汇聚窗口、步幅为2(每个块后分辨率减半)的最大汇聚层
定义一个名为vgg_block的函数来实现一个VGG块
该函数有三个参数,分别对应于卷积层的数量num_convs、输入通道的数量in_channels 和输出通道的数量out_channels
1 | def vgg_block(num_convs, in_channels, out_channels): |
网络结构
与AlexNet、LeNet一样,VGG网络可以分为两部分:第一部分主要由卷积层和汇聚层组成,第二部分由全连接层组成
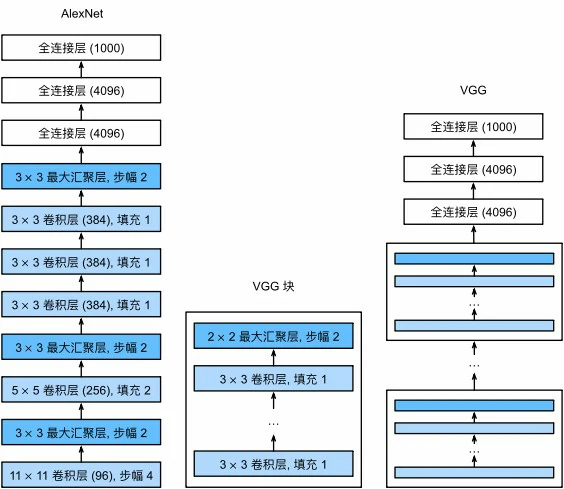
VGG神经网络连接几个VGG块(在vgg_block函数中定义),其中有超参数变量conv_arch
该变量指定了每个VGG块里卷积层个数和输出通道数,全连接模块则与AlexNet中的相同
原始VGG网络有5个卷积块,其中前两个块各有一个卷积层,后三个块各包含两个卷积层
第一个模块有64个输出通道,每个后续模块将输出通道数量翻倍,直到该数字达到512。由于该网络使用8个卷积层和3个全连接层,因此它通常被称为VGG-11
1 | # conv_arch 的内容为(num_convs, out_channels),输入通道由程序逻辑推导 |
下面的代码实现了VGG-11,可以通过在conv_arch上执行for循环来简单实现
1 | def vgg(conv_arch): |
构建一个高度和宽度为224的单通道数据样本,以观察每个层输出的形状
1 | net = vgg(conv_arch) |
1 | Layer Output Shape |
正如从代码中所看到的,在每个块输出的高度和宽度减半,最终高度和宽度都为7,最后再展平表示,送入全连接层处理
为了方便打印,把打印封装为函数
如果没有遍历sub_layer会将多个卷积视为一个块,只会输出一个
1 | def print_net_shapes(net, X): |
模型训练
由于VGG-11比AlexNet计算量更大,因此构建了一个通道数较少的网络,足够用于训练Fashion-MNIST数据集
1 | ratio = 4 # 减少输出通道数倍率 |
除了使用略高的学习率外,模型训练过程与AlexNet类似
1 | lr, num_epochs, batch_size = 0.05, 10, 128 |
1 | epoch 1, loss 0.675, acc 0.755 |

1 | loss 0.163, train acc 0.940, test acc 0.928 |
小结
- VGG-11使用可复用的卷积块构造网络,不同的VGG模型可通过每个块中卷积层数量和输出通道数量的差异来定义
- 块的使用导致网络定义的非常简洁,使用块可以有效地设计复杂的网络
- 在VGG论文中,他们发现深层且窄的卷积(3×3)比浅层且宽的卷积更有效
思考题
与AlexNet相比,VGG的计算要慢得多,而且它还需要更多的显存。分析出现这种情况的原因
模型 卷积层数 卷积核大小 通道增长 参数量 AlexNet 5 层 11×11, 5×5, 3×3 96→256→384→384→256 ~61M VGG-11 8 层 3×3 64→128→256→512→512 ~132M VGG 的卷积层数量更多,通道数更多,参数几乎翻倍,中间特征图分辨率保持更高
尝试将Fashion-MNIST数据集图像的高度和宽度从224改为96,这对实验有什么影响
卷积层的输出特征图变小,全连接层输入维度随之改变,计算效率会得到提高
不同的VGG
| 模型 | 卷积层数 | 全连接层 | 总层数(卷积+全连接) |
|---|---|---|---|
| VGG-11 (A型) | 8 | 3 | 11 |
| VGG-16 (D型) | 13 | 3 | 16 |
| VGG-19 (E型) | 16 | 3 | 19 |
卷积块设计:
| Block | 输出通道 | 池化后尺寸 | VGG-11 | VGG-16 | VGG-19 |
|---|---|---|---|---|---|
| 1 | 64 | 112×112 | Conv×1 | Conv×2 | Conv×2 |
| 2 | 128 | 56×56 | Conv×1 | Conv×2 | Conv×2 |
| 3 | 256 | 28×28 | Conv×2 | Conv×3 | Conv×4 |
| 4 | 512 | 14×14 | Conv×2 | Conv×3 | Conv×4 |
| 5 | 512 | 7×7 | Conv×2 | Conv×3 | Conv×4 |
性能对比:
| 模型 | 参数量 | GFLOPs | Top-5 准确率 | 特征 |
|---|---|---|---|---|
| VGG-11 | ≈ 133M | ≈ 7.6 | ~89.5% | 最浅、最快、参数最少 |
| VGG-16 | ≈ 138M | ≈ 15.3 | ~92.7% | 标准版,最常用 |
| VGG-19 | ≈ 144M | ≈ 19.6 | ~93.0% | 最深、最慢、参数略多 |
VGG-16是性能与代价的最佳平衡点,从VGG-16到VGG-19精度几乎不变,但计算量大幅增加
所以工业界和研究中最常用的是 VGG-16
如果想要修改VGG模型,只需要修改conv_arch,以下为VGG-16结构
1 | conv_arch = ((2, 64), (2, 128), (3, 256), (3, 512), (3, 512)) |
网络中的网络(NiN)
LeNet、AlexNet和VGG都有一个共同的设计模式:通过一系列的卷积层与汇聚层来提取空间结构特征,然后通过全连接层对特征的表征进行处理
AlexNet和VGG对LeNet的改进主要在于如何扩大和加深这两个模块
如果在这个过程的早期使用了全连接层,可能会完全放弃表征的空间结构,NiN提供了一个非常简单的解决方案:在每个像素的通道上分别使用多层感知机(Lin et al., 2013)
NiN块
NiN的核心思想是:在每个像素位置上应用一个1×1卷积(可视为局部全连接层),把空间维度的每个像素当作独立样本,通道维度作为其特征进行学习
VGG和NiN及它们的块之间主要架构差异:
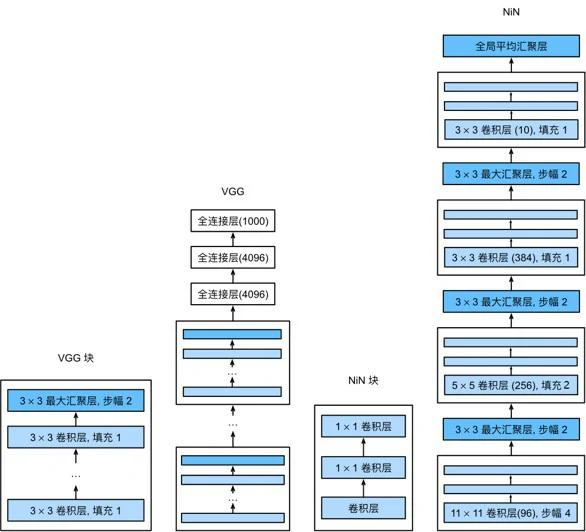
NiN块以一个普通卷积层开始,输入输出通道数通常由用户设置,后面是两个1×1的卷积层,这两个卷积层充当带有ReLU激活函数的逐像素全连接层
1 | def nin_block(in_channels, out_channels, kernel_size, stride, padding): |
网络结构
最初的NiN在AlexNet后不久提出,结构类似,仍用11×11、5×5、3×3卷积和步幅为2的3×3最大池化,输出通道数相同,主要区别在于用NiN块替代全连接层,并通过**全局平均汇聚层(global average pooling layer)**输出类别
NiN设计显著减少参数量,但在实际中可能会增加训练模型的时间
1 | net = nn.Sequential( |
创建一个数据样本来查看每个块的输出形状
1 | X = torch.rand(size=(1, 1, 224, 224)) |
1 | Layer Output Shape |
训练模型
使用Fashion-MNIST来训练模型
1 | lr, num_epochs, batch_size = 0.1, 10, 128 |
1 | epoch 1, loss 2.084, acc 0.224, time 61.468 |

1 | loss 0.554, train acc 0.814, test acc 0.787 |
小结
- NiN使用由一个卷积层和多个1×1卷积层组成的块,该块可以在卷积神经网络中使用,以允许更多的每像素非线性
- NiN去除了容易造成过拟合的全连接层,将它们替换为全局平均汇聚层(即在所有位置上进行求和),该汇聚层通道数量为所需的输出数量
- 移除全连接层可减少过拟合,同时显著减少NiN的参数
- 虽然NiN的性能不比VGG,但它取消全连接层的思想很重要,为后来的 GoogLeNet、ResNet 等模型奠定了基础
思考题
为什么NiN块中有两个1×1卷积层?
层次 功能 类比 普通卷积 提取局部空间特征 “卷积滤波器” 第一个 1×1 卷积 对通道特征进行第一次变换 “小型全连接层” 第二个 1×1 卷积 进一步学习通道间非线性关系 “堆叠的多层感知机” 第一个用于提取和压缩通道特征,第二个用于再次组合与非线性变换,增强表示能力
如果删除一个1×1卷积,模型仍然可以训练,但准确率通常下降,收敛更慢,并且表达能力变弱,尤其在复杂数据集上
一次性直接将384×5×5的表示缩减为10×5×5的表示会出现什么问题
如果直接用1×1卷积将通道数压缩到10,这会让非线性减弱,学不到高阶的通道交互,而且梯度通道太窄,容易欠拟合,将优化压力给到前面层
通常会导致泛化变差,准确率降低
计算NiN的资源使用情况
参数数量
第一层(11×11, 1→96)参数约 11×11×1×96 = 11,616
第二层(5×5, 96→256)参数约 5×5×96×256 = 614,400
第三层(3×3, 256→384)参数约 3×3×256×384 = 884,736
整网加起来约 8M,比AlexNet少得多,因为少了全连接层
计算量
$$
\mathrm{MAC_s} = K_h\times K_w\times C_{in}\times H_{out}\times W_{out}\times C_{out}
$$
虽然1×1卷积核简单,但是输出通道多,计算量也不小,FLOPs约为1~1.5GFLOPs,小于VGG
含并行连结的网络(GoogleNet)
GoogLeNet(Szegedy et al., 2015)借鉴NiN的串联结构,并在此基础上做了改进,通过组合不同大小的卷积核来解决卷积核尺寸选择问题
接下来实现的GoogLeNet稍微简化,省略了一些为稳定训练而添加的特殊特性,因为现在有了更好的训练方法,这些特性不是必要的
Inception块
在GoogLeNet中,基本的卷积块被称为Inception块(Inception block)
这很可能得名于电影《盗梦空间》(Inception),因为电影中的一句话“We need to go deeper”

Inception块由四条并行路径组成。前三条路径使用窗口大小为1×1,3×3,5×5的卷积层,从不同空间大小中提取信息;中间的两条路径在输入上执行1×1卷积,以减少通道数从而降低模型的复杂性;第四条路径使用3×3最大汇聚层,然后使用1×1卷积层来改变通道数
核心思想是同时用多尺度卷积去提取不同层次的特征,再把它们拼在一起
这四条路径都使用合适的填充来使输入与输出的高和宽一致,最后将每条线路的输出在通道维度上连结,并构成Inception块的输出
在Inception块中,通常调整的超参数是每层输出通道数
1 | class Inception(nn.Module): |
为什么GoogLeNet这个网络如此有效呢?
不同尺寸的卷积滤波器能捕捉图像中不同尺度的特征,小核捕捉局部细节,大核关注全局结构,从而同时学习细节与整体特征,增强了模型的表达能力
网络结构
GoogLeNet一共使用9个Inception块和全局平均汇聚层的堆叠来生成其估计值,Inception块之间的最大汇聚层可降低维度
第一个模块类似于AlexNet和LeNet,Inception块的组合从VGG继承,全局平均汇聚层从NiN继承,避免了在最后使用全连接层

逐一实现GoogLeNet的每个模块
第一模块和之前的网络相同,使用一个7×7卷积层,输出64个通道,步幅为2,填充为3
1 | b1 = nn.Sequential( |
第二模块使用两个卷积层,第一个卷积层输出64通道,第二个卷积层输出192通道
1 | b2 = nn.Sequential( |
从第三模块开始有Inception块
第三模块串联两个完整的Inception块,输入通道数为192
第一个Inception块的输出通道数为64+128+32+32=256,四个路径的输出通道比为2:4:1:1
第二条和第三条路径首先将输入通道的数量分别减少为1/2(96)和1/12(16),然后连接第二个卷积层
第二个Inception块将输出通道数增加到128+192+96+64=480,四个路径之间的输出通道数量比为4:6:3:2,第二条和第三条路径首先将输入通道的数量分别减少为1/2(128)和1/8(32)
1 | b3 = nn.Sequential( |
第四模块更加复杂,它串联了5个Inception块,其输出通道数分别是192+208+48+64=512,160+224+64+64=512,128+256+64+64=512,112+288+64+64=528和256+320+128+128=832
路径的通道分配和第三模块类似,含3×3卷积层的第二条路径输出最多通道,其次是仅含1×1卷积层的第一条路径,之后是含5×5卷积层的第三条路径和含3×3最大汇聚层的第四条路径
第二、第三条路径都会先按比例减小通道数,这个比例在各个Inception块中都略有不同
1 | b4 = nn.Sequential( |
第五模块包含两个Inception块,输出通道数为256+320+128+128=832和384+384+128+128=1024,其中每条路径通道数的分配思路和第三、第四模块中的一致,只是在具体数值上有所不同
需要注意的是,第五模块的后面紧跟输出层,该模块同NiN一样使用全局平均汇聚层,将每个通道的高和宽变成1,最后将输出变成二维数组,再接上一个输出个数为标签类别数的全连接层
1 | b5 = nn.Sequential( |
GoogLeNet模型的计算复杂,而且不如VGG那样便于修改通道数
为了使Fashion-MNIST上的训练短小精悍,将输入的高和宽从224降到96,这简化了计算
下面演示各个模块输出的形状变化
1 | X = torch.rand(size=(1, 1, 96, 96)) |
1 | Layer Output Shape |
训练模型
在训练之前,将图片转换为96×96分辨率
1 | lr, num_epochs, batch_size = 0.01, 10, 128 |
1 | epoch 1, loss 0.957, acc 0.650, time 42.424 |

1 | loss 0.260, train acc 0.903, test acc 0.878 |
小结
- Inception块相当于一个有4条路径的子网络,它通过不同窗口形状的卷积层和最大汇聚层来并行抽取信息,并使用1×1卷积层减少每像素级别上的通道维数从而降低模型复杂度
- GoogLeNet将多个设计精细的Inception块与其他层(卷积层、全连接层)串联起来,其中Inception块的通道数分配之比是在ImageNet数据集上通过大量的实验得来的
- GoogLeNet和它的后继者们一度是ImageNet上最有效的模型之一:它以较低的计算复杂度提供了类似的测试精度
思考题
使用GoogLeNet的最小图像大小是多少?
层 操作 尺寸变化 输出尺寸(H×W) 输入 - - 224×224 Conv1 7×7, stride=2, padding=3 ↓ 一半 112×112 MaxPool1 3×3, stride=2 ↓ 一半 56×56 Conv2 3×3, stride=1 保持 56×56 MaxPool2 3×3, stride=2 ↓ 一半 28×28 Inception 3a+3b stride=1 保持 28×28 MaxPool3 3×3, stride=2 ↓ 一半 14×14 Inception 4a+4b stride=1 保持 14×14 MaxPool4 3×3, stride=2 ↓ 一半 7×7 Inception 5a+5b stride=1 保持 7×7 Global AvgPool 通道合并 所以在进入Global AvgPool前尺寸减少了$2^5$次,所以理论最小是32
将AlexNet、VGG和NiN的模型参数大小与GoogLeNet进行比较。后两个网络架构是如何显著减少模型参数大小的?
模型 参数量 主要节省策略 关键创新 AlexNet(2012) 60M 无优化 首次大规模 CNN VGG-16(2014) 138M 深层结构但全连接太大 多层小卷积 NiN(2013) 8M 1×1 Conv + GAP,去除FC Network in Network GoogLeNet (2014) 6.8M Inception + 通道压缩 + GAP 模块化多尺度设计 VGG和AlexNet的参数主要来源于三个巨大的全连接层
NiN 通过 1×1 卷积和全局平均池化消除了冗余的全连接层
GoogLeNet 在此基础上进一步通过 多分支 + 通道压缩 把参数量进一步压缩
批量规范化
训练深层神经网络是十分困难的,特别是在较短的时间内使他们收敛更加棘手
批量规范化(batch normalization,BN)(Ioffe and Szegedy, 2015)是一种流行且有效的技术,可持续加速深层网络的收敛速度
实际挑战
数据预处理的方式通常会对最终结果产生巨大影响
批量规范化是为了解决训练神经网络时输入分布不稳定、梯度难以收敛等问题。在训练时对每一层的小批量输入计算均值与方差,将其规范化为均值为0、方差为1的分布,再通过可学习的拉伸参数(scale)$\gamma$以及偏移参数(shift)$\beta$恢复模型的表达能力
这样做可以:
- 减少不同层之间分布的剧烈变化,加快收敛;
- 使训练对学习率不那么敏感;
- 起到一定正则化作用,减轻过拟合
需要注意的是,BN 依赖于小批量的统计特性,因此批量太小会导致不稳定或无效
从形式上来说$\mathbf{x} \in \mathcal{B}$表示一个来自小批量的输入,批量规范化根据以下表达式转换$\mathbf{x}$
$$
BN(x) = \gamma \cdot \frac{x - \hat \mu_B}{\hat \sigma_B} + \beta
$$
批量均值与方差分别为
$$
\begin{aligned}
\hat\mu_\mathcal B &= \frac{1}{| B|} \sum_{x \in B} x \\
\hat\sigma^2_B &= \frac{1}{| B|} \sum_{x \in B} (x - \hat\mu_B)^2 + \epsilon
\end{aligned}
$$
在方差估计值中添加一个小的常量以确保永远不会尝试除以零,训练中的随机性与噪声可视为一种正则化,有助于泛化
(Teye et al., 2018)和(Luo et al., 2018)分别将批量规范化的性质与贝叶斯先验相关联,这些理论揭示了为什么批量规范化最适应50~100范围中等批量大小的难题
批量规范化在训练和预测阶段的行为不同:
- 训练模式:使用当前小批量的均值和方差进行规范化,因为此时无法获得全数据统计
- 预测模式:使用在训练过程中累计得到的全局均值和方差,对输入进行稳定规范化
批量规范化层
批量规范化和其他层之间的一个关键区别是,由于批量规范化在完整的小批量上运行,因此不能像以前在引入其他层时那样忽略批量大小
批量规范化层置于全连接层/卷积层后,激活函数之前
全连接层
设全连接层的输入为$\mathbf{x}$,激活函数为$\phi$,批量规范化的运算符为$\mathrm{BN}$,使用批量规范化的全连接层的输出的计算详情如下
$$
\mathbf{h} = \phi(\mathrm{BN}(\mathbf{W}\mathbf{x} + \mathbf{b}) ).
$$
均值和方差是在应用变换的“相同”小批量上计算的
卷积层
当卷积有多个输出通道时,需要对这些通道的每个输出执行批量规范化,每个通道都有自己的拉伸和偏移参数,这两个参数都是标量
设一个小批量中有$m$个样本,每个通道输出的特征图尺寸为$p×q$,那么需要对每个输出通道的$m \cdot p \cdot q$个元素上同时执行批量规范化
预测过程
批量规范化在训练与预测阶段的行为不同,训练时依赖当前小批量数据的均值和方差进行规范化,因此包含随机噪声和批次间波动,而预测阶段则需要稳定、确定的输出,不再使用小批量统计量,而是采用在训练过程中通过移动平均得到的全局均值和方差
BN层与暂退法类似,在训练和推理阶段的计算方式并不相同
底层实现
1 | def batch_norm(X, gamma, beta, moving_mean, moving_var, eps, momentum): |
在可以创建一个正确的BatchNorm层,这个层将保持适当的参数:拉伸gamma和偏移beta,这两个参数将在训练过程中更新,将保存均值和方差的移动平均值,以便在模型预测期间随后使用
将此功能集成到一个自定义层中,其代码主要处理数据移动到训练设备(如GPU)、分配和初始化任何必需的变量、跟踪移动平均线(此处为均值和方差)等问题,这里代码需要指定整个特征的数量,但在深度学习框架中的API不需要考虑这个问题
1 | class BatchNorm(nn.Module): |
带入LeNet
批量规范化是在卷积层或全连接层之后、相应的激活函数之前应用的
1 | net = nn.Sequential( |
和以前一样,将在Fashion-MNIST数据集上训练网络,但区别是学习率大得多
批量规范化通过控制中间层输入的分布,让网络在数值上对学习率更加鲁棒,因此可以安全使用更大的学习率,以加快收敛并提升泛化
1 | lr, num_epochs, batch_size = 1.0, 10, 256 |
1 | epoch 1, loss 0.759, acc 0.727, time 9.976 |

1 | loss 0.270, train acc 0.902, test acc 0.871 |
来看看从第一个批量规范化层中学到的拉伸参数gamma和偏移参数beta
1 | net[1].gamma.reshape((-1,)), net[1].beta.reshape((-1,)) |
1 | (tensor([0.5371, 2.9680, 4.2053, 3.2385, 0.3399, 3.5118], |
简洁实现
可以直接使用深度学习框架中定义的BatchNorm,net中修改一下即可,只需要输入输出通道数作为参数
1 | net = nn.Sequential( |
通常高级API变体运行速度快得多,因为它的代码已编译为C++或CUDA,而自定义代码由Python实现
1 | train_ch6(net, train_iter, test_iter, num_epochs, lr, try_gpu()) |
1 | epoch 1, loss 0.647, acc 0.760, time 9.311 |

1 | loss 0.251, train acc 0.908, test acc 0.885 |
争议
批量规范化常被直观地认为能让优化过程更平滑、更稳定,然而这种“直觉解释”并不等同于科学原理,事实上至今仍未完全理解即使是简单神经网络(如多层感知机、传统CNN)为何能如此有效泛化
BN的提出者在论文中将其效果归因于减少内部协变量偏移(internal covariate shift),即训练过程中各层输入分布的变化,但这种解释存在两点问题:
- 内部协变量偏移与严格意义上的**协变量偏移(covariate shift)**不同,命名并不严谨
- 该解释仅是一种模糊的直觉,并未真正揭示 BN 成功的机制
其他研究者提出了新的观点:BN 的作用机制可能与原论文的解释相反(Santurkar et al., 2018),其真正效果更接近于改善优化几何性质,使损失函数更光滑
无论解释如何分歧,批量规范化几乎成为现代神经网络训练的标准组成部分,尤其在图像分类任务中表现突出,并在学术界获得了数万次引用
小结
- 在模型训练过程中,批量规范化利用小批量的均值和标准差,不断调整神经网络的中间输出,使整个神经网络各层的中间输出值更加稳定
- 批量规范化在全连接层和卷积层的使用略有不同
- 批量规范化层和暂退层一样,在训练模式和预测模式下计算不同
- 批量规范化有许多有益的副作用,主要是正则化
思考题
在使用批量规范化之前,是否可以从全连接层或卷积层中删除偏置参数?为什么?
可以删除偏置参数,因为BN的$\beta$拥有“平移能力”,原本线性层的偏置就变得多余
大多数现代实现(包括 ResNet、VGG-BN、DenseNet等)都是在有 BN 的情况下,关闭前一层的 bias,这不仅简化了参数,还能略微提高训练效率,避免无意义的梯度更新
比较使用和不使用批量规范化情况下的学习率
BN会扩大稳定学习率范围,所以用BN可以把学习率开得更大
是否需要在每个层中进行批量规范化?
删除全连接层后面的批量规范化对结果影响不大,所以不是非要每个层
- 卷积层:在每个卷积层后(激活函数前)加 BN 通常是有益的,因为早期特征分布变化大
- 全连接层:加 BN 的收益远小于卷积层,常见做法是只在第一个或前几个全连接层上使用
在浅层网络(如LeNet)中,只需在卷积层后加 BN 即可,在更深网络(如ResNet、DenseNet),BN才几乎每层使用
对比批量规范化和暂退法
特征 批量规范化 暂退法 引入的噪声 来自小批量统计(均值、方差的随机性) 来自神经元随机屏蔽 噪声作用层面 连续扰动——数值被平滑缩放 离散扰动——神经元直接置零 对梯度的影响 稳定梯度流 阻断部分梯度路径,增加训练噪声 对模型行为 加速收敛、提高数值稳定性 提高泛化、减轻过拟合 推理阶段 去噪(使用滑动均值/方差) 去噪(缩放激活值) BN的噪声可以视作一种隐式贝叶斯正则,但强度有限
Dropout 的噪声是显式的、较强的随机化机制
根据网络类型进行选择,BN对卷积层效果更好,Dropout对全连接层效果更好
场景 常见做法 卷积网络(如LeNet、ResNet) 通常用 BN,不用 Dropout 全连接层较多(如传统 MLP) 通常用 Dropout,BN 作用有限 小数据集或易过拟合任务 同时使用 BN + Dropout
但 Dropout 需放在 BN 之后(否则统计不稳定)大模型 + 大数据 通常使用 BN,不再需要 Dropout
残差网络(ResNet)
随着设计越来越深的网络,深刻理解“新添加的层如何提升神经网络的性能”变得至关重要
函数类
假设有一类特定的神经网络架构$\mathcal{F}$,它包括学习速率和其他超参数设置,对于所有$f \in \mathcal{F}$存在一些参数集(例如权重和偏置),这些参数可以通过在合适的数据集上进行训练而获得
假设$f^\ast$是真正想要找到的函数,如果$f^\ast \in \mathcal{F}$那可以轻而易举的训练得到它,但通常不会那么幸运,因此将尝试找到一个函数$f^\ast_\mathcal{F}$,这是在$\mathcal{F}$中的最佳选择
给定一个具有$\mathbf{X}$特性和$\mathbf y$标签的数据集,可以尝试通过解决以下优化问题来找到它
$$
f^\ast_\mathcal{F} := \mathop{\mathrm{argmin}}_f L(\mathbf{X}, \mathbf{y}, f) \text{ subject to } f \in \mathcal{F}.
$$
想要近似,唯一合理的可能性是设计一个更强大的架构$\mathcal{F}’$,但是如果$\mathcal{F} \not\subseteq \mathcal{F}’$则无法保证新的体系“更近似”
对于**非嵌套函数(non-nested function)**类,较复杂的函数类并不总是向真函数$f^\ast$靠拢(复杂度由1到6递增),在左图中虽然$\mathcal{F}_3$比$\mathcal{F}_1$更接近$f^\ast$,但$\mathcal{F}_6$更远了
对于右侧的**嵌套函数(nested function)**类可以避免这个问题
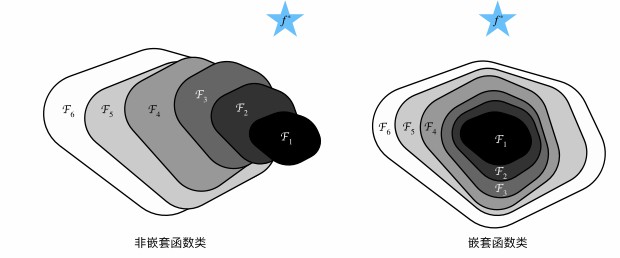
只有当较复杂的函数类包含较简单的函数类时,模型性能才有可能提升
在深度神经网络,如果新增层能学到恒等映射(identity function),则新旧模型表现相同,更深的模型具备更强表示能力,能够找到更优解,从而更容易降低训练误差
针对这一问题,何恺明等人提出了残差网络(ResNet)(He et al., 2016)
残差网络的核心思想是:每一层在学习新特征的同时,都能够轻松地保留原始输入,从而让网络更容易表示目标函数
**残差块(residual blocks)**便诞生了,这个设计对如何建立深层神经网络产生了深远的影响
残差块
在神经网络中,假设输入为$x$,理想映射为$f(\mathbf{x})$(作为激活函数的输入),左图的虚线框直接拟合$f(\mathbf{x})$,右图的虚线框则学习残差$f(\mathbf{x}) - \mathbf{x}$,实践表明,残差映射往往更容易优化
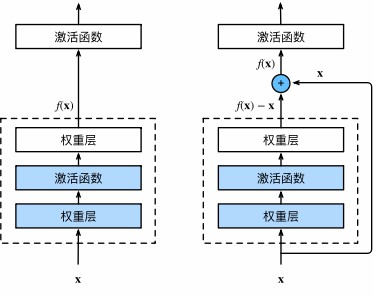
左图为正常块,右图展示了ResNet的基本单元——残差块,其中输入可通过跨层连接直接向前传播,从而加速训练并缓解梯度消失问题
若将右图中加权层的权重与偏置设为0,即得到恒等映射
当理想映射接近恒等映射时,残差结构能轻松捕捉这种细微偏差
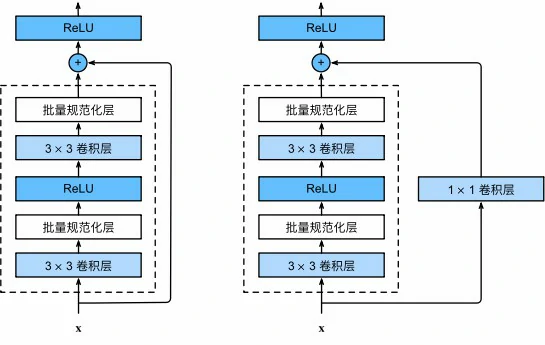
ResNet沿用了VGG完整的3×3卷积层设计,残差块里首先有2个有相同输出通道数的3×3卷积层,每个卷积层后接一个批量规范化层和ReLU激活函数,通过跨层数据通路,跳过这2个卷积运算,将输入直接加在最后的ReLU激活函数前
这样的设计要求2个卷积层的输出与输入形状一样从而使它们可以相加,如果想要改变通道数,就需要引入一个额外的1×1卷积层来将输入变换成需要的形状后再做相加运算
残差块的实现
1 | class Residual(nn.Module): #@save |
此代码生成两种类型的网络,当use_1x1conv=False时应用ReLU非线性函数之前,将输入添加到输出;当use_1x1conv=True时,添加通过1×1卷积调整通道和分辨率
来查看输入和输出形状一致的情况
1 | block = Residual(3,3) |
增加输出通道数的同时,减半输出的高和宽
1 | blk = Residual(3, 6, use_1x1conv=True, strides=2) |
网络结构
ResNet的第一层跟GoogLeNet一样:在输出通道数为64、步幅为2的7×7卷积层后,接步幅为2的3×3的最大汇聚层,不同之处在于ResNet每个卷积层后增加了批量规范化层
1 | b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3), |
GoogLeNet在后面接了4个由Inception块组成的模块,而ResNet则使用4个由残差块组成的模块构成,每个模块内的残差块输出通道数相同
因为在b1中最大池化已经下采样了,所以第一个模块步幅为1,不再下采样
| 场景 | 是否使用 1×1 卷积 | 步幅 | 作用 |
|---|---|---|---|
| 第一个模块 | 否 | 1 | 保持通道数与尺寸 |
| 其他模块的第一个残差块 | 是 | 2 | 通道数翻倍、尺寸减半 |
| 其他模块中的后续块 | 否 | 1 | 保持不变 |
来实现这个模块,对第一个模块做了特别处理
1 | def resnet_block(input_channels, num_channels, num_residuals, |
在ResNet加入所有残差块,这里每个模块使用2个残差块
1 | b2 = nn.Sequential(*resnet_block(64, 64, 2, first_block=True)) |
最后,与GoogLeNet一样,在ResNet中加入全局平均汇聚层,以及全连接层输出
1 | net = nn.Sequential(b1, b2, b3, b4, b5, |
每个模块有4个卷积层(不包括恒等映射的1×1卷积层),加上第一个7×7卷积层和最后一个全连接层,共有18层,这种模型通常被称为ResNet-18
通过配置不同的通道数和模块里的残差块数可以得到不同的ResNet模型,例如更深的含152层的ResNet-152
虽然ResNet的主体架构跟GoogLeNet类似,但ResNet架构更简单,修改也更方便
下图为完整的ResNet-18架构
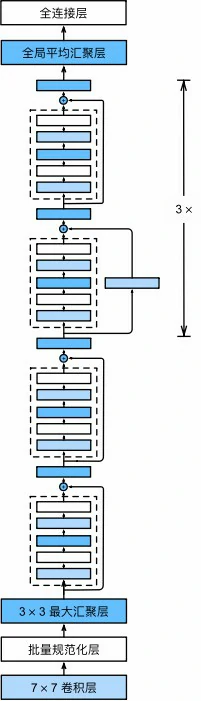
在训练ResNet之前,观察一下ResNet中不同模块的输入形状是如何变化的
在之前所有架构中,分辨率降低,通道数量增加,直到全局平均汇聚层聚集所有特征
1 | X = torch.rand(size=(1, 1, 224, 224)) |
1 | Layer Output Shape |
训练模型
在Fashion-MNIST数据集上训练ResNet
1 | lr, num_epochs, batch_size = 0.05, 10, 256 |
1 | epoch 1, loss 0.649, acc 0.820 |

1 | loss 0.018, train acc 0.996, test acc 0.913 |
非常夸张的训练集精确度啊
小结
- 学习嵌套函数是训练神经网络的理想情况,在深层神经网络中,学习另一层作为恒等映射较容易(尽管这是一个极端情况)
- 残差映射可以更容易地学习同一函数,例如将权重层中的参数近似为零
- 利用残差块可以训练出一个有效的深层神经网络:输入可以通过层间的残余连接更快地向前传播
- ResNet对随后的深层神经网络设计产生了深远影响
思考题
Inception块与残差块之间的主要区别是什么?在删除了Inception块中的一些路径之后,它们是如何相互关联的?
对比二者:
特征 Inception块 残差块(Residual Block) 主要动机 增加网络的宽度(多尺度特征提取) 增加网络的深度(更容易优化的深层结构) 核心结构 多条卷积路径并行(1×1、3×3、5×5 等)再拼接 一条主路径 + 一条恒等捷径,进行相加 特征融合方式 把各路径输出在通道维度上堆叠 把输入与变换后的特征直接相加 设计目的 让网络在同一层中感受不同尺度的特征 让网络学习残差,稳定训练 对梯度传播的影响 并行路径增加特征表达能力,但深度增加后仍易梯度衰减 恒等连接保证梯度能直接后传,不易消失 两者的关联:
把Inception块中的多分支路径删掉,只保留一条主要的卷积路径,这个结构就很接近一个普通的卷积层,如果再加上一条跨层的恒等连接,就演化为了残差块
ResNet变体
参考ResNet论文(He et al., 2016)中的表1,学习多种变体
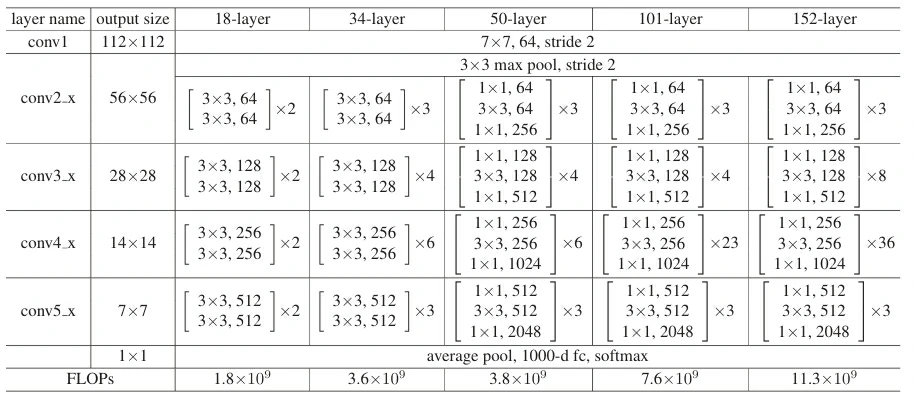
| 模型 | Block 类型 | [conv2_x, conv3_x, conv4_x, conv5_x] | 总层数 |
|---|---|---|---|
| ResNet-18 | BasicBlock | [2, 2, 2, 2] | 18 |
| ResNet-34 | BasicBlock | [3, 4, 6, 3] | 34 |
| ResNet-50 | Bottleneck | [3, 4, 6, 3] | 50 |
| ResNet-101 | Bottleneck | [3, 4, 23, 3] | 101 |
| ResNet-152 | Bottleneck | [3, 8, 36, 3] | 152 |
在ResNet-50/101/152 都用到了Bottleneck,每个残差块由三个卷积核组成,其中1×1卷积的主要作用是降维+升维
以50-layers conv2_x为例:
| 卷积层 | 核大小 | 通道变化 | 作用 |
|---|---|---|---|
| 第一层 | 1×1 | 256 → 64 | 降维,减少计算量 |
| 第二层 | 3×3 | 64 → 64 | 提取特征 |
| 第三层 | 1×1 | 64 → 256 | 升维,恢复通道数以便残差相加 |
这样使得3×3卷积不会在高通道上操作,降低计算量
1×1卷积几乎不增加计算负担,却能控制通道数
在ResNet v2中,作者将“卷积层、批量规范化层和激活层”架构更改为“批量规范化层、激活层和卷积层”架构
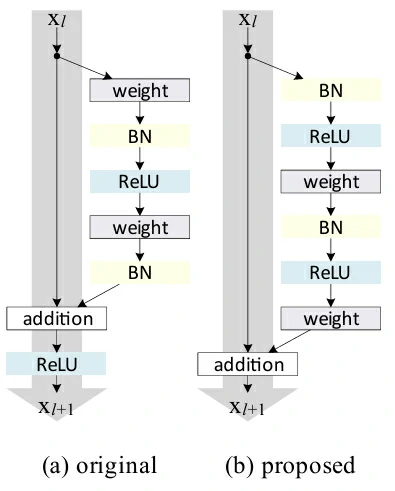
| 类型 | 顺序 | 关键特性 |
|---|---|---|
| ResNet v1 | Conv → BN → ReLU → Conv → BN → Add → ReLU | 加法后再激活(post-activation) |
| ResNet v2 | BN → ReLU → Conv → BN → ReLU → Conv → Add | 加法前激活(pre-activation) |
post-activation在浅层时没问题,但在非常深的网络中,梯度在跨层传播时容易衰减,因为 BN 和 ReLU 在加法之后才起作用
pre-activation将BN和ReLU放在卷积层之前,残差相加不再经过激活函数,使残差连接成为真正的恒等映射,更利于梯度直接传播
稠密连接网络(DenseNet)
ResNet极大地改变了如何参数化深层网络中函数的观点,稠密连接网络(DenseNet)(Huang et al., 2017)在某种程度上是ResNet的逻辑扩展
从ResNet到DenseNet
任意函数的泰勒展开式它把这个函数分解成越来越高阶的项,在$x$接近0时
$$
f(x) = f(0) + f’(0) x + \frac{f’’(0)}{2!} x^2 + \frac{f’’’(0)}{3!} x^3 + \ldots.
$$
同样ResNet将函数展开为
$$
f(\mathbf{x}) = \mathbf{x} + g(\mathbf{x})
$$
就是说,ResNet将$f$分解为两部分:一个简单的线性项和一个复杂的非线性项
再向前拓展一步,想将$f$拓展成超过两部分的信息呢,一种方案便是DenseNet
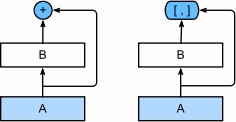
ResNet(左)和DenseNet(右)的关键区别在于,DenseNet输出是连接而不是如ResNet的简单相加
因此,在应用越来越复杂的函数序列后,执行从$\mathbf {x}$到其展开式的映射
$$
\mathbf{x} \to \left[
\mathbf{x},
f_1(\mathbf{x}),
f_2([\mathbf{x}, f_1(\mathbf{x})]), f_3([\mathbf{x}, f_1(\mathbf{x}), f_2([\mathbf{x}, f_1(\mathbf{x})])]), \ldots\right].
$$
最后,将这些展开式结合连接到多层感知机中,再次减少特征的数量
DenseNet这个名字由变量之间的“稠密连接”而得来,最后一层与之前的所有层紧密相连
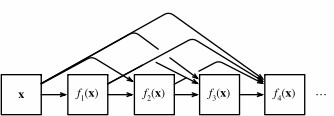
稠密网络主要由2部分构成:稠密块(dense block)和过渡层(transition layer)
前者定义如何连接输入和输出,而后者则控制通道数量,使其不会太复杂
稠密块体
DenseNet使用了ResNet改良版的“批量规范化、激活和卷积”架构,首先实现一下这个架构
1 | def conv_block(input_channels, num_channels): |
一个稠密块由多个卷积块组成,每个卷积块使用相同数量的输出通道
在前向传播中,将每个卷积块的输入和输出在通道维上连结
1 | class DenseBlock(nn.Module): |
| 第几层 | 输入通道数 | 输出通道数 | 输入来自 |
|---|---|---|---|
| 第 1 层 | 64 | 32 | 原始输入 |
| 第 2 层 | 64 + 32 = 96 | 32 | 输入 + 第 1 层输出 |
| 第 3 层 | 64 + 32×2 = 128 | 32 | 输入 + 第 1、2 层输出 |
每一层不仅接收上一层的输出,还接收前面所有层的特征图,这种模式被称为特征重用(feature reuse)
定义一个有2个卷积块,输出通道数为10的DenseBlock,使用通道数为3的输入时,会得到通道数为3+2×10=23的输出
1 | blk = DenseBlock(2, 3, 10) |
卷积块的通道数控制了输出通道数相对于输入通道数的增长,因此也被称为增长率(growth rate)
过渡层
由于每个稠密块都会带来通道数的增加,使用过多则会过于复杂化模型,过渡层可以用来控制模型复杂度,通过1×1卷积层来减少通道数,并使用步幅为2的平均汇聚层减半高和宽,从而进一步降低模型复杂度
1 | def transition_block(input_channels, num_channels): |
对刚刚的输出使用通道数为10的过渡层,此时输出的通道数减为10,高和宽均减半
1 | blk = transition_block(23, 10) |
网络结构
DenseNet首先使用同ResNet一样的单卷积层和最大汇聚层
1 | b1 = nn.Sequential( |
类似于ResNet使用的4个残差块,DenseNet使用的是4个稠密块
与ResNet类似,可以设置每个稠密块使用多少个卷积层,这里设成4使得与刚刚的ResNet-18保持一致
稠密块里的卷积层通道数(即增长率)设为32,所以每个稠密块将增加128个通道
在每个模块之间,ResNet通过步幅为2的残差块减小高和宽,DenseNet则使用过渡层来减半高和宽,并减半通道数
1 | # num_channels为当前的通道数 |
与ResNet类似,最后接上全局汇聚层和全连接层来输出结果
1 | net = nn.Sequential( |
测试一下模型
1 | X = torch.rand(size=(1, 1, 224, 224)) |
1 | Layer Output Shape |
训练模型
由于这里使用了比较深的网络,将输入高和宽从224降到96来简化计算
1 | lr, num_epochs, batch_size = 0.1, 10, 256 |
1 | epoch 1, loss 0.500, acc 0.827, time 35.426 |

1 | loss 0.129, train acc 0.954, test acc 0.882 |
小结
- 在跨层连接上,不同于ResNet中将输入与输出相加,稠密连接网络(DenseNet)在通道维上连结输入与输出
- DenseNet的主要构建模块是稠密块和过渡层
- 在构建DenseNet时,需要通过添加过渡层来控制网络的维数,从而再次减少通道的数量
思考题
为什么DenseNet在过渡层使用平均汇聚层而不是最大汇聚层?
DenseNet 与 ResNet 的主要不同在于每一层都把前面所有层的输出拼接起来,用作输入
这种密集连接意味着:
- 网络内部的特征是累积的
- 每一层都依赖前面层的信息
- 信息流要尽量顺畅、完整、不被破坏
平均池化能平滑压缩空间维度,同时保留全局分布特征,不会“只选最亮的像素”
DenseNet的优点之一是其模型参数比ResNet小,为什么呢?
在ResNet中,每一层都要“重新计算”很多通用底层特征(例如边缘、纹理),而DenseNet 直接复用前面层的特征图,不用重新卷积计算这些特征,因此减少参数
模型 层数 参数量 (M) Top-1 Error (%) ResNet-50 50 25.6M 23.9 DenseNet-121 121 8.0M 25.0 ResNet-152 152 60.2M 23.0 DenseNet-169 169 14.1M 24.0 DenseNet 参数量只有 ResNet 的三分之一甚至更少,却达到相近精度
DenseNet一个诟病的问题是内存或显存消耗过多,为什么?
DenseNet参数少,但中间特征多且需要全部保留参与拼接,在现代GPU上显存的主要消耗主要来源于特征图
假设一个 block 有 4 层,每层输出通道数 = 32
层 输入通道 (ResNet) 输入通道 (DenseNet) 1 64 64 2 64 96 (=64+32) 3 64 128 (=64+32×2) 4 64 160 (=64+32×3) 在 DenseNet 中,输入通道逐层增加,这意味着卷积层要处理越来越多的特征图
在 ImageNet 级别的模型上,DenseNet-121/169显存消耗比ResNet-50/101高约 1.5~2 倍,这也是 DenseNet 没有被工业界大规模取代 ResNet 的一个重要原因
总结
只有LeNet输入的是28×28的小尺寸图片,其余的都是在ImageNet上测试的,所以输入均为3×224×224
| 意义模型 | 年份 | 核心创新 | 意义 | 局限 |
|---|---|---|---|---|
| LeNet | 1998 | 卷积 + 池化 | 开创CNN | 太浅,Sigmoid饱和 |
| AlexNet | 2012 | ReLU + Dropout + GPU | 让CNN复活 | 结构设计经验化,参数多 |
| VGG | 2014 | 小卷积核深堆叠 | 简洁、通用 | 参数暴涨,训练成本高 |
| NiN | 2013 | 1×1卷积 + GAP | 通道融合、轻量 | 模型深度有限,精度略低 |
| GoogLeNet | 2014 | 多尺度Inception | 高效、强大 | 结构复杂,设计依赖经验 不易泛化到其它任务 |
| ResNet | 2015 | 残差连接 | 深度可扩展 | 依赖BN |
| DenseNet | 2017 | 全连接特征流 | 特征复用、梯度顺畅 | 显存大 |
BN → ReLU → Conv 是ResNet后比较固定的模块



.webp)
.webp)